Background
Post-training techniques such as instruction tuning and reinforcement learning from human feedback (RLHF) are essential for refining language models. However, open-source post-training resources have lagged behind proprietary methods, limiting transparency and accessibility. Previous works like TÜLU 2 and Zephyr-β introduced open recipes but relied on less advanced and simplified methods.
To address these gaps, this paper introduced TÜLU 3, an advanced open-source framework incorporating rigorous data curation, novel techniques like RLVR, and an extensive evaluation suite. TÜLU 3 enhanced core skills such as reasoning, coding, and precise instruction following while outperforming state-of-the-art open and proprietary models in specific benchmarks.
This research bridged the gap by offering comprehensive open resources, including datasets, training recipes, and evaluation frameworks. It also pushed the boundaries of post-training with cutting-edge methods. By addressing shortcomings in dataset overlap through decontamination, TÜLU 3 ensures fairness and accuracy in evaluations. By releasing all artifacts, TÜLU 3 enabled further advancements in open post-training techniques.
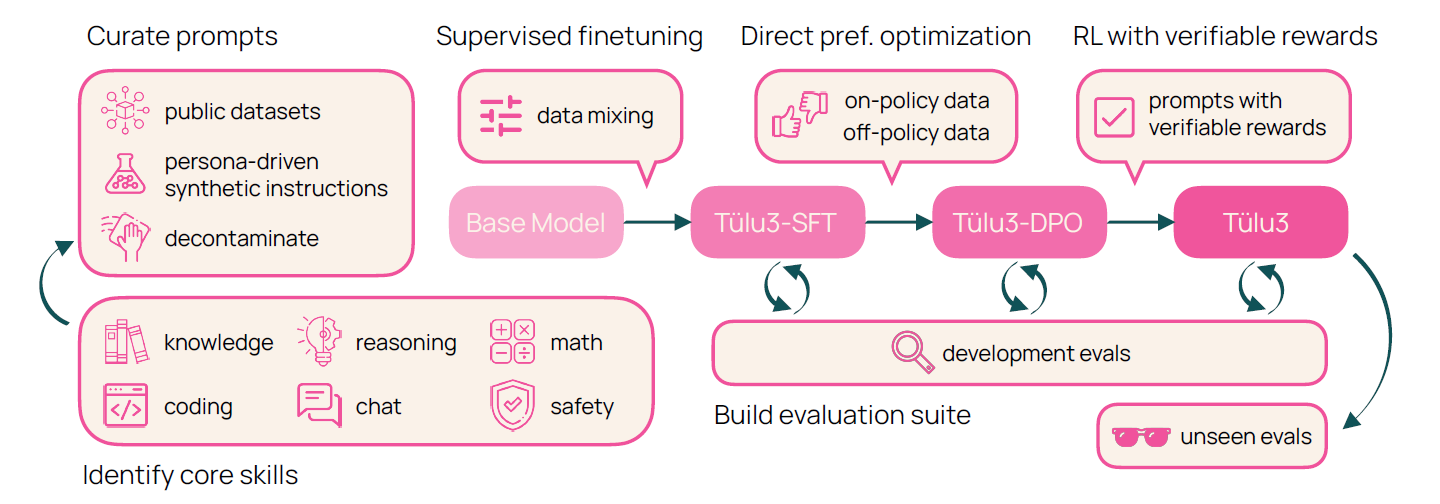 An overview of the TÜLU 3 recipe. This includes data curation targeting general and target capabilities, training strategies, and a standardized evaluation suite for the development and final evaluation stage.
An overview of the TÜLU 3 recipe. This includes data curation targeting general and target capabilities, training strategies, and a standardized evaluation suite for the development and final evaluation stage.
TÜLU 3 Overview and Data
TÜLU 3 enhanced post-training techniques for language models by blending open and closed fine-tuning methods. Building on InstructGPT techniques and the advancements of TÜLU 2, it incorporated innovations like RLVR to improve targeted capabilities such as knowledge recall, reasoning, and coding.
The model’s four-stage pipeline—data curation, supervised fine-tuning (SFT), preference tuning, and RLVR—was guided by a robust evaluation framework (TÜLU 3 EVAL), ensuring reproducibility. TÜLU 3 outperformed open-weight models and even closed models like GPT-3.5 and GPT-4 on tasks such as MATH, GSM8K, and safety benchmarks. The project emphasized open-source contributions by releasing its data, training methods, and evaluation tools, advancing the language model post-training field.
TÜLU 3’s data strategy focused on curating diverse prompts to improve model performance across tasks such as math, coding, multilingualism, and safety. Prompts were sourced from publicly available datasets like WildChat and FLAN v2 and supplemented with persona-driven synthetic data generation, which expanded the diversity and scope of training tasks.
The dataset underwent rigorous decontamination to prevent overlaps between training and evaluation data, ensuring test integrity. Problematic instances identified through n-gram-based matching were systematically removed to avoid data leakage. This approach ensured robust and unbiased datasets that supported model evaluation and development.
SFT and Preference Finetuning
SFT customized pre-trained models for specific tasks, addressing challenges in balancing diverse datasets. For TÜLU 3, the team refined skills by identifying gaps in a baseline model (Llama 3.1) and enhancing those areas using high-quality datasets. Iterative adjustments, including filtering low-quality responses and generating new data, led to improved performance.
A particular focus was placed on curating task-specific datasets, such as WildChat for safety and FLAN v2 for multilingual understanding, which improved metrics like instruction following and safety compliance. While adding more SFT data generally enhanced performance, over-saturation with low-quality data negatively impacted metrics like TruthfulQA. Optimized training involved careful data selection, loss function tuning, and hyperparameter adjustments, achieving superior results through balanced and efficient processes.
This study examined preference fine-tuning methods in TÜLU 3, leveraging DPO and proximal policy optimization (PPO). A reward model (RM) distinguished preferred responses and trained them with both on-policy and off-policy preference data. The approach scaled effectively, integrating diverse synthetic prompts and real-world data.
Scaling unique prompts and unused prompts further boosted results. Analysis revealed that specific combinations, such as WildChat and IF datasets, significantly improved targeted skills like instruction following and safety compliance, while certain datasets had limited impact.
RLVR
RLVR was a novel training method for language models on tasks with verifiable outcomes, such as math problem-solving and instruction following. RLVR replaced the reward model in traditional RLHF with a verification function, providing rewards only when outputs were verifiably correct. Using PPO, RLVR was applied across tasks like grade school math eight thousand (GSM8K), MATH, and IF evaluation (IFEval), achieving improved targeted performance without sacrificing general capabilities.
Key findings included significant improvements in math benchmarks such as GSM8K, better results from using verifiable rewards alone rather than combining them with reward model scores, and enhanced scalability to large models (up to 70 billion parameters) through optimized GPU utilization.
Evaluation Framework
The TÜLU 3 EVAL was designed to assess model performance with reproducibility, generalization to unseen tasks, and fairness across diverse models. It included an open language model evaluation standard (OLMES) for transparent and standardized assessments.
The framework emphasized separating training and testing datasets to ensure fair generalization assessments. TÜLU 3’s evaluation regime refined benchmarks like massive multitask language understanding (MMLU), TruthfulQA, and HumanEval with techniques like zero-shot chain-of-thought (CoT) prompting and context-sensitive answer extraction strategies.
Safety benchmarks evaluated models’ ability to refuse unsafe prompts and respond to benign ones accurately, using tools like WildGuard. The unseen suite tested real-world usability by employing concise prompts and minimal prescriptive instructions, ensuring alignment with natural user behaviors and expectations.
Conclusion
In conclusion, the researchers presented a comprehensive open-source framework for enhancing language models, leveraging Llama 3.1 and advanced post-training techniques like SFT, DPO, and RLVR. The authors included datasets, training recipes, and evaluation benchmarks to ensure reproducibility and adaptation across domains. TÜLU 3 outperformed proprietary models such as GPT-3.5 and GPT-4 in targeted tasks, including math reasoning, coding, and safety compliance.
Its robust evaluation framework emphasized fairness, generalization, and safety. By releasing all artifacts, TÜLU 3 bridged the gap in open post-training resources, fostering transparency and advancing language model capabilities.
Sources:
Journal reference: