Discover how DeepSeek-V3 leverages groundbreaking innovations like FP8 precision and multi-token prediction to deliver record-breaking performance while redefining efficiency in AI training.
 Benchmark performance of DeepSeek-V3 and its counterparts. Research: DeepSeek-V3 Technical Report
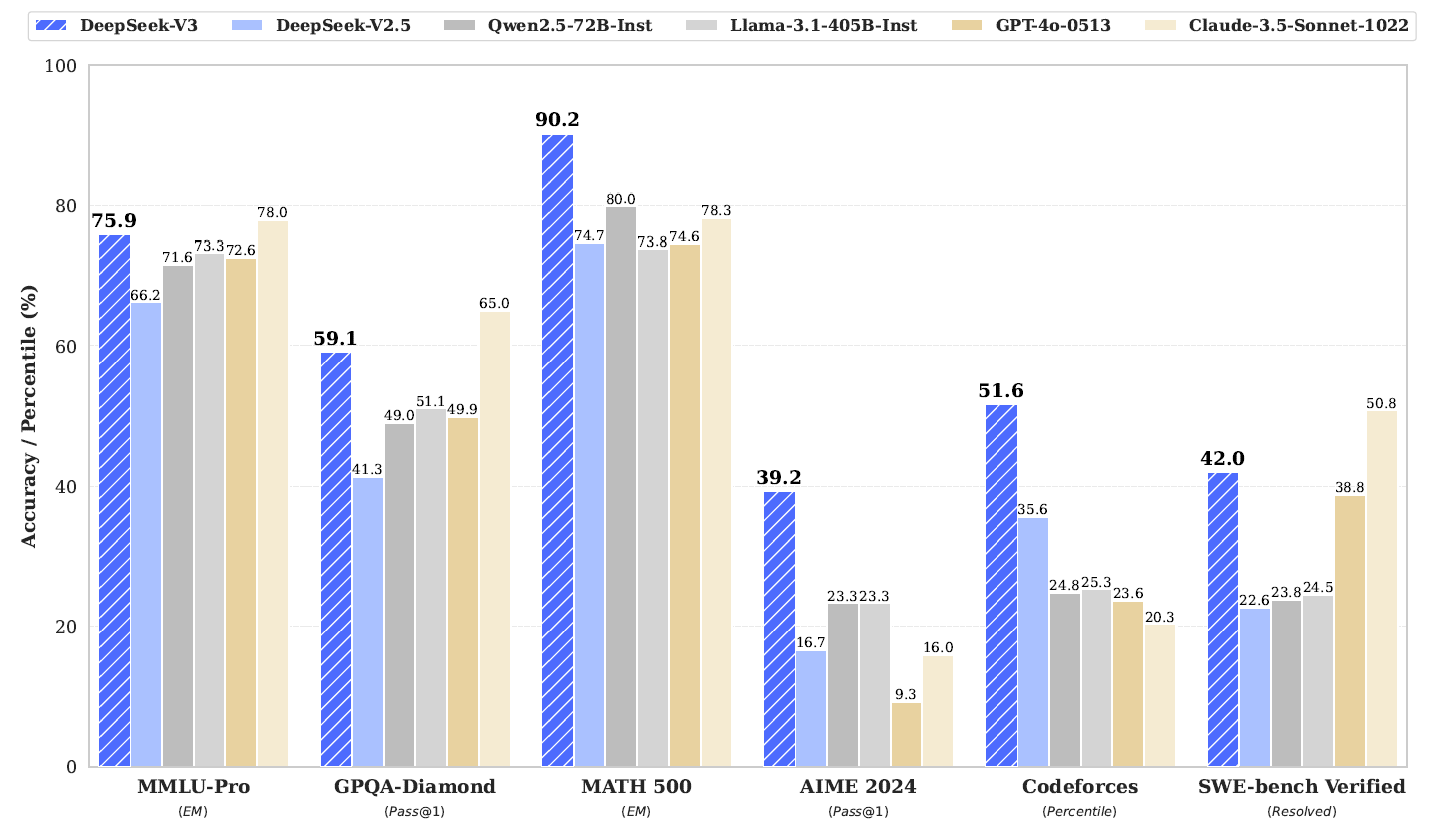
Benchmark performance of DeepSeek-V3 and its counterparts. Research: DeepSeek-V3 Technical Report
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
In an article recently submitted to the arXiv preprint* server, DeepSeek researchers introduced DeepSeek-V3, a 671 billion (B) parameter mixture-of-experts (MoE) language model optimized for efficiency and cost-effective training. It employed multi-head latent attention (MLA) and a unique auxiliary-loss-free load-balancing strategy, trained on 14.8 trillion tokens. With supervised fine-tuning and reinforcement learning, it achieved state-of-the-art performance comparable to closed-source models, requiring only 2.788 million (M) graphic processing unit (GPU) hours for stable training without setbacks.
Background
Large language models (LLMs) have advanced significantly, pushing the boundaries of open-source artificial intelligence (AI) capabilities to rival closed-source systems. Previous works, such as the DeepSeek, LLaMA, and Qwen series, introduced models with scalable architectures but often faced challenges in efficient training, inference, and maintaining load balance during execution. Despite notable achievements, gaps remain in cost-effective scaling, reasoning performance, and optimizing training frameworks for large-scale models.
Addressing these limitations, DeepSeek-V3 leveraged a 671B parameter MoE model, leveraging innovations like auxiliary-loss-free load balancing and multi-token prediction (MTP) objectives. Additionally, it pioneered FP8 mixed-precision training and efficient pipeline parallelism, dramatically reducing training costs while ensuring stability. Evaluations demonstrated its dominance across benchmarks such as MMLU-Pro, GPQA-Diamond, and coding tests. Pre-trained on 14.8 trillion tokens and fine-tuned with reinforcement learning, DeepSeek-V3 achieved state-of-the-art results across knowledge, reasoning, and coding benchmarks, establishing itself as the strongest open-source LLM to date.
Architecture
DeepSeek-V3 built upon the transformer framework with innovations aimed at efficient inference and cost-effective training. The architecture introduced MLA and MoE, enhancing performance while addressing computational challenges.
MLA reduced memory usage during inference by compressing key-value (KV) and query representations. This low-rank compression minimized KV cache size without compromising performance. It employed rotary positional embedding (RoPE) for enhanced positional encoding, achieving efficiency comparable to standard multi-head attention.
MoE optimized the feed-forward networks by using fine-grained experts, including shared and routed ones. A novel auxiliary-loss-free load balancing strategy dynamically adjusted expert usage to prevent imbalance and computational inefficiencies, outperforming traditional methods reliant on auxiliary losses. The complementary sequence-wise balance loss was introduced to enhance balance during computation further.
MTP enabled the model to predict multiple tokens simultaneously, improving training efficiency and future token prediction capabilities. Sequential MTP modules extended the prediction depth, maintaining a causal chain for robust token representation. Due to its effective load balancing and deployment strategies, DeepSeek-V3 avoided token dropping during training and inference. These features collectively ensured performance improvements while reducing computational overhead.
Infrastructure
DeepSeek-V3 employed a state-of-the-art training framework designed for scalability, efficiency, and precision in large-scale LLM development. It utilized 2048 NVIDIA H800 GPUs interconnected via NVLink and InfiniBand (IB), optimized with the DualPipe algorithm, which overlapped computation and communication to minimize delays and improve GPU utilization.
Key infrastructure advancements included custom cross-node communication kernels leveraging IB and NVLink to optimize data transfer, dynamic token routing to reduce bottlenecks, and memory-saving strategies like backpropagation recomputation and parameter sharing. Advanced FP8 fine-grained quantization strategies were used to scale activations and weights dynamically, ensuring high precision even with low-bit representations. The framework incorporated FP8 mixed-precision training to enhance speed and reduce memory usage while maintaining numerical stability.
Inference strategies separated prefilling and decoding, employing advanced parallelism and communication optimization to balance throughput and latency. Fine-grained quantization and dynamic scaling were incorporated into tensor cores, enabling higher computational efficiency and lower memory overhead. Hardware design recommendations emphasized unified communication networks, increased FP8 accumulation precision, and support for fine-grained quantization in tensor cores, ensuring scalable and efficient AI training and deployment.
Pre-Training and Post-Training
DeepSeek-V3 built upon its predecessor, DeepSeek-V2, introducing innovations in data handling, model architecture, and training efficiency. The pre-training corpus included 14.8 trillion diverse tokens, focusing on multilingual, mathematical, and programming datasets. Strategies like fill-in-middle (FIM) and prefix-suffix-middle (PSM) enhanced contextual prediction. Evaluations highlighted notable advancements on benchmarks such as Arena-Hard, with multilingual benchmarks demonstrating >85% performance. A byte-level byte pair encoding (BPE) tokenizer with 128 thousand (K) tokens improved multilingual compression while mitigating token boundary bias through training adjustments.
The model boasted 61 transformer layers, 671 B parameters (37 B activated per token), and MoE layers for efficiency. Context windows extended up to 128K using YaRN, and training employed scalable learning rate schedules and parallelism, achieving cost efficiency at 180K GPU hours per trillion tokens. Performance comparisons against Qwen2.5 and LLaMA-3.1 showcased significant gains across reasoning and coding tasks.
Post-training fine-tuning involved 1.5 M instruction-tuning instances covering reasoning, coding, and creative tasks. Reasoning data generated by DeepSeek-R1 used concise, accurate formats, while non-reasoning responses, vetted by human annotators, maintained high quality. A cosine decay learning rate schedule and data masking ensured training isolation. Reinforcement learning employed reward models tailored for deterministic and subjective tasks, with group relative policy optimization (GRPO) driving efficient policy updates.
Conclusion
In conclusion, DeepSeek-V3 represented a milestone in open-source AI development, blending efficiency, innovation, and cost-effectiveness. With its 671B parameter MoE architecture, MLA, and auxiliary-loss-free load balancing, the model set new training and inference efficiency standards. By leveraging innovations such as the DualPipe algorithm, FP8 mixed-precision training, and dynamic load balancing strategies, DeepSeek-V3 bridged the performance gap with closed-source models like GPT-4o and Claude-3.5.
Pre-trained on 14.8 trillion tokens and fine-tuned with reinforcement learning, DeepSeek-V3 achieved state-of-the-art results in reasoning, coding, and multilingual tasks, rivaling closed-source models and solidifying its role as a breakthrough in open-source AI research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., Dai, D., Guo, D., Yang, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo, F., . . . Pan, Z. (2024). DeepSeek-V3 Technical Report. ArXiv. https://arxiv.org/abs/2412.19437