Built on the Qwen2.5 architecture and pre-trained on over 5.5 trillion tokens, these models demonstrated advanced code generation and reasoning capabilities, outperforming larger models across more than ten benchmarks. The series incorporates unique architectural features, such as specialized tokens like FIM (Fill-in-the-Middle) tokens and repository identifiers, enabling it to handle complex code structures effectively.
Using refined data techniques, Qwen2.5-Coder showed balanced performance in code tasks while retaining general and mathematical skills. The training leveraged hierarchical filtering and rigorous decontamination to ensure high-quality datasets, minimizing overlaps with test sets like HumanEval. This release aimed to advance code intelligence research and encourage real-world developer adoption through permissive licensing.
Qwen2.5-Coder-32B
Background
Past work on large language models and code-specific large language models (LLMs), such as StarCoder, CodeLlama, DeepSeekCoder, and CodeQwen1.5, showcased significant advancements in coding tasks but still lagged behind top proprietary models like Claude-3.5-Sonnet and generative pre-trained model (GPT-4o).
Despite achieving superior performance in various coding benchmarks, these models, both open-source and proprietary, often fell short compared to the latest state-of-the-art LLMs.
Qwen2.5-Coder Architecture
The Qwen2.5-Coder architecture, derived from Qwen2.5, scales across six model sizes (0.5B to 32B parameters), with variations in hidden size, layers, and query heads. The smaller models use embedding tying, while larger ones forgo it to optimize scalability. It inherits Qwen2.5's vocabulary and introduces unique tokens to improve code understanding, such as FIM tokens and repository identifiers, for handling complex code structures during pretraining. These innovations, combined with a vocabulary size of 151,646 tokens, enhance the models' long-context handling capabilities, supporting sequences up to 128K tokens.
Multi-Stage Training Overview
The pre-training of the Qwen2.5-Coder model relies on five primary data types: source code data, text-code grounding data, synthetic data, Math data, and text data. Public code repositories from GitHub (spanning 92 programming languages) were rigorously filtered using a coarse-to-fine hierarchical approach.
The dataset was created by gathering public code repositories from GitHub. It covers 92 programming languages and includes additional data from Pull Requests, Commits, Jupyter Notebooks, and Kaggle datasets.
The data was cleaned using rule-based methods to ensure high quality. A large-scale text-code dataset was also curated from the standard crawl, combining documentation, blogs, and tutorials with a custom filtering approach that improved the dataset's quality.
For the synthetic data, CodeQwen1.5, the predecessor model, was used to generate large datasets, and an executor was applied to validate the generated code. Math Data from Qwen2.5-Math was integrated into the pre-training set without affecting the model's code generation performance to enhance mathematical capabilities. Text data derived from the Qwen2.5 general language corpus was included while ensuring no overlap with the code data.
The training policy followed a three-stage approach: file-level pre-training, repo-level pre-training, and instruction tuning. The file-level pre-training used 5.2 trillion tokens, focusing on individual code files, while repo-level pre-training extended the context length to 32,768 tokens, further enhancing long-context capabilities. Instruction tuning was enriched with multilingual datasets and a collaborative framework that synthesized instruction data across multiple languages, supported by checklist-based scoring methods.
In summary, Qwen2.5-Coder's pre-training used diverse, high-quality datasets and a rigorous cleaning pipeline. It was followed by a multi-stage training process incorporating file-level, repo-level, and instruction-based tuning to optimize the model for code generation tasks across multiple programming languages.
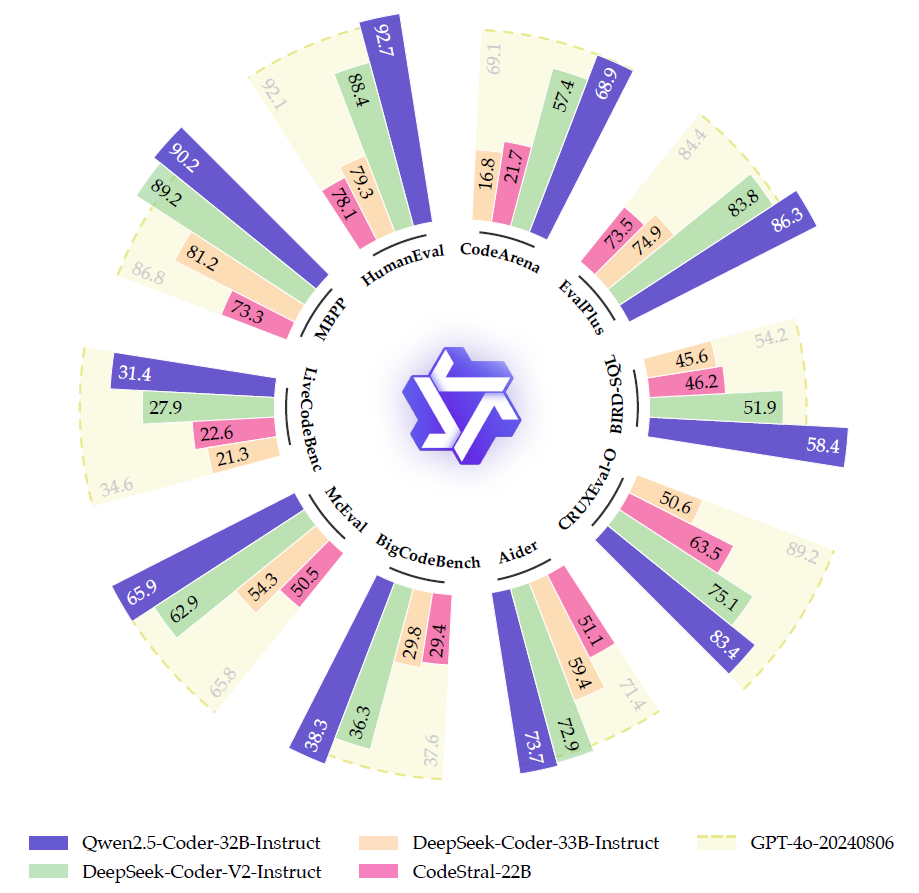
Leading Performance in Coding
The evaluation of base models for code generation, code completion, and related tasks focused on critical metrics using popular benchmarks such as HumanEval, massive biology and programming problems (MBPP), BigCodeBench, and MultiPL-E. The Qwen2.5-Coder series stood out among the models assessed, particularly in code generation and multi-programming language performance.
The series, across various sizes (0.5B to 32B parameters), demonstrated state-of-the-art results, surpassing even larger models like StarCoder2 in several tasks. For example, Qwen2.5-Coder-7B achieved a HumanEval score of 61.6%, outperforming DS-Coder-33B (54.9%) despite being significantly smaller.
For code generation, Qwen2.5-Coder models, including the 7B variant, showed impressive capabilities on BigCodeBench-Complete, showcasing the model's strong generalization potential for more complex instruction-following tasks. The series also excelled in multi-language evaluations, achieving over 60% proficiency in five out of eight languages, including C++, Java, and TypeScript, demonstrating its versatility beyond Python.
Additionally, in the MultiPL-E evaluation, which assesses model performance across multiple programming languages, Qwen2.5-Coder achieved over 60% proficiency in five out of eight languages, demonstrating versatility beyond Python, which had been the primary focus of earlier evaluations.
The Qwen2.5-Coder models excelled in code completion tasks, especially the 32B variant, which topped several completion benchmarks like Humaneval-FIM, CrossCodeEval, and RepoEval. Compared to other models, Qwen2.5-Coder improved performance, with the 1.5B variant outperforming most models with over 6 billion parameters. Its Fill-in-the-Middle (FIM) training strategy played a pivotal role in enabling contextually coherent code completion. These rigorous evaluations confirmed the model's ability to generate contextually coherent code snippets based on preceding and succeeding code contexts.
Qwen2.5-Coder demonstrated outstanding performance across multiple coding tasks, establishing itself as one of the leading open-source models in code generation and completion. Its long-context capabilities, supported by advanced repo-level pretraining, uniquely position it for real-world software development applications.
Conclusion
To summarize, this work introduced Qwen2.5-Coder, an advanced code generation model based on Qwen2.5. Extensive pre-training and post-training were performed on large-scale datasets, focusing on high-quality code data curation. The model demonstrated strong performance as a coding assistant, and future research will focus on scaling up data and model size. Enhancements to reasoning and multilingual capabilities are also planned, leveraging insights from multilingual instruction synthesis and large-context pretraining.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Sources:
Journal reference:
- Preliminary scientific report.
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., Dang, K., Fan, Y., Zhang, Y., Yang, A., Men, R., Huang, F., Zheng, B., Miao, Y., Quan, S., . . . Lin, J. (2024). Qwen2.5-Coder Technical Report. ArXiv. https://arxiv.org/abs/2409.12186