The LVSM model reshapes the future of 3D rendering by bypassing traditional biases, delivering photorealistic images from sparse inputs and setting a new benchmark for flexibility and quality in computer vision.
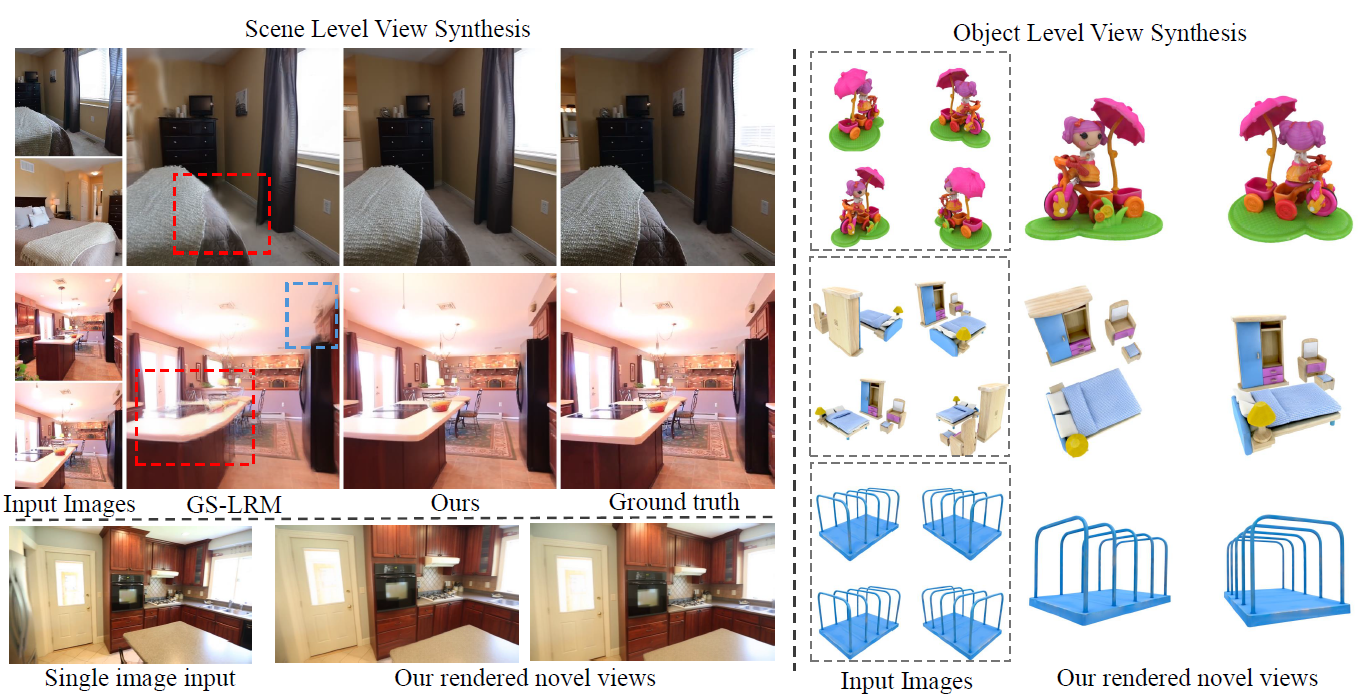
LVSM supports feed-forward novel view synthesis from sparse posed image inputs (even from a single view) on both objects and scenes. LVSM achieves significant quality improvements compared with the previous SOTA method, i.e., GS-LRM (Zhang et al., 2024). Research: LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
In an article recently submitted to the arXiv preprint* server, researchers at Cornell University, The University of Texas at Austin, and Massachusetts Institute of Technology presented the large view synthesis model (LVSM), a transformer-based method for generating novel views from sparse input images. They introduced two architectures: an encoder-decoder model that creates learned scene representations and a decoder-only model that directly generates novel views without intermediate representations. Both approaches eliminated traditional three-dimensional (3D) biases and demonstrated state-of-the-art performance in novel view synthesis (NVS), achieving significant quality improvements (up to 3.5 dB PSNR gain) while requiring fewer computational resources.
Background
NVS has been a significant challenge in computer vision and graphics, traditionally relying on various 3D inductive biases, such as handcrafted structures and priors, to enhance synthesis quality. Recent advancements, including neural radiance fields (NeRF) and 3D Gaussian splatting (3DGS), introduced new 3D representations and rendering techniques that improved performance but still faced limitations in flexibility and adaptability due to their reliance on predefined structures. While large reconstruction models (LRMs) have made strides in minimizing architectural biases, they continue to depend on representation-level biases, which constrain their generalization and scalability.
This paper addressed these gaps by introducing the LVSM, a novel transformer-based framework that synthesizes novel-view images from sparse inputs without relying on predefined rendering equations or 3D structures. The LVSM comprises two architectures: an encoder-decoder model that utilizes learned scene representations and a decoder-only model that directly converts input images to target views, bypassing intermediate representations entirely. By minimizing 3D inductive biases, the LVSM achieved significant improvements in quality, generalization, and zero-shot adaptability, outperforming existing state-of-the-art methods and pushing the boundaries of NVS capabilities.
Approach and Model Architecture
The proposed LVSM method synthesizes target images using sparse input images with known camera data. The input images, tokenized into patches, are processed alongside target-view tokens that represent the novel camera perspective. LVSM employed transformer-based architectures, utilizing Plücker ray embeddings derived from camera parameters to enhance the synthesized views.
The method uses two architectures: a decoder-only and an encoder-decoder model. The decoder-only model processes input tokens directly to generate the target view, similar to a generative pre-trained transformer (GPT)-like model. Inspired by traditional transformers, the encoder-decoder model first produces a latent scene representation before decoding it into the target view. This model is advantageous in rendering efficiency by compressing 3D scenes into latent tokens. Both architectures used self-attention layers without biases like attention masks, allowing LVSM to operate efficiently across various input and target configurations. During synthesis, LVSM conditions target-view tokens on input tokens, transforming them into output tokens to regress red-green-blue (RGB) values for the target view. The model used a loss function that combined mean squared error and perceptual loss, enabling high-quality photorealistic rendering.
Experimental Setup and Performance Analysis
The LVSM was trained on separate object-level and scene-level datasets for rendering realistic 3D views from limited two-dimensional (2D) images. For object-level training, LVSM used the Objaverse dataset and tested it on the Google scanned objects (GSO) and Amazon Berkeley objects (ABO) datasets, applying four input views and ten target views.
Scene-level training used the RealEstate10K dataset, following the train/test split from previous studies. To stabilize training, LVSM implemented query-key normalization (QK-Norm) to prevent gradient issues and accelerated training with FlashAttention-v2, gradient checkpointing, and mixed-precision training. These optimizations contributed to more efficient model performance, especially in computationally limited settings.
The model was trained on 64 A100 graphic processing units (GPU) with a peak learning rate of 4e-4, reaching high-resolution outputs at 512 pixels after fine-tuning. LVSM’s encoder-decoder variant and decoder-only variant showed significant improvements over prior methods like GS-LRM, achieving superior rendering in terms of geometric accuracy and texture detail. The decoder-only LVSM, which bypassed 3D biases, achieved up to a 3 decibel (dB) peak signal-to-noise ratio (PSNR) gain on ABO and GSO datasets at higher resolutions. As the number of input views increased, the model scaled well, particularly the decoder-only variant, which effectively utilized the additional information.
LVSM’s flexibility extended to limited GPU setups; when trained on a single GPU, a smaller version, LVSM-small, surpassed other single-GPU models. Additionally, the encoder-decoder structure supported efficient rendering by compressing 3D scenes into latent tokens, while the decoder-only model improved quality with more input views but at higher computational costs. In contrast to previous NVS methods, LVSM provides significant advantages in both resource efficiency and output quality.
Conclusion
In conclusion, the researchers introduced the LVSM, a transformer-based framework that enhances novel view synthesis by reducing reliance on 3D inductive biases. Featuring two architectures—encoder-decoder and decoder-only—LVSM effectively bypasses traditional 3D representations, learning directly from data to improve flexibility and scalability.
The decoder-only model showcased remarkable scalability and quality, while the encoder-decoder variant enhanced inference speed. Both architectures demonstrated significant performance gains across various benchmarks, representing a crucial advancement in the pursuit of robust, generalizable novel view synthesis in complex real-world applications.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference:
- Preliminary scientific report.
Jin, H., Jiang, H., Tan, H., Zhang, K., Bi, S., Zhang, T., Luan, F., Snavely, N., & Xu, Z. (2024). LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias. ArXiv.org. DOI:10.48550/arXiv.2410.17242, https://arxiv.org/abs/2410.17242