Advancements in Visual Representation Technologies
The development of image representation has primarily focused on two paradigms. One emphasizes high-level semantics, as shown in models like contrastive language-image pretraining (CLIP). The other focuses on pixel-level fidelity, which can be seen in variational autoencoders (VAEs). While semantic models excel in understanding abstract concepts, they often struggle with fine visual details. Conversely, reconstruction models effectively retain visual information but lack robust semantic representation. This division has hindered advancements in applications requiring both detailed image understanding and generation.
Therefore, this research addresses a pivotal question: Can a single representation effectively encapsulate both semantic understanding and detailed visual fidelity? The paper underscores the importance of leveraging recent advancements in text-to-image (T2I) diffusion models, which inherently balance semantic richness with intricate visual information through their denoising processes. By utilizing the strengths of pre-trained T2I models, researchers can utilize their ability to capture semantic richness and visual complexities.
ViLex: A Novel Language Model for Image Representation
In this paper, the authors presented ViLex as a self-supervised learning model that encodes images directly into text-based vocabulary to retain its key features. The goal was to generate tokens that not only reconstruct input images with high fidelity but also capture their semantic information, such as object types and spatial layouts. The training process repurposes a frozen T2I diffusion model, like Imagen, as a decoder within an autoencoder framework, which enriches the model's ability to integrate both high-level semantics and visual detail.
ViLex operates through an autoencoder architecture consisting of two components: a vision encoder and an attention-pooling layer. The vision encoder extracts visual representations from input images. At the same time, the attention pooling layer transforms these representations into ViLex tokens that can be utilized independently or in conjunction with natural language tokens. This dual functionality allows ViLex to prompt T2I models with both visual and textual cues, thereby enabling multimodal interactions.
The training involves optimizing the ViLex model using an image reconstruction loss, with gradients backpropagating from the frozen diffusion model. Additionally, the researchers employed the TailDrop strategy, a dynamic visual token compression method, which randomly drops the last few ViLex tokens during training to encourage earlier tokens to combine richer semantic content. This approach enhances the model's efficiency and adaptability by enabling token count adjustments to balance the semantic richness and visual detail during inference.
The researchers conducted experiments to validate ViLex's efficacy. They compared its performance against traditional text embeddings and other state-of-the-art models using Microsoft’s common objects in context (MS-COCO) dataset.
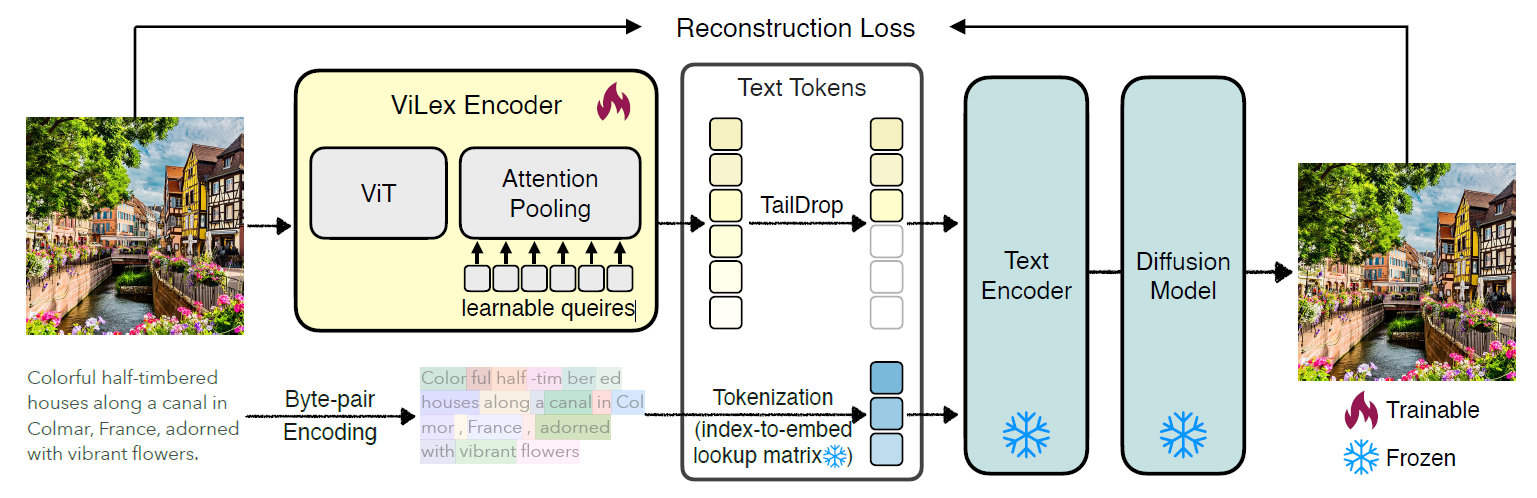
The pipeline of ViLex: We learn a Visual Lexicon from a frozen diffusion model using an image reconstruction loss. After training, ViLex can be directly used as the “text-prompt” to a frozen text encoder, e.g., CLIP or T5, enabling the re-creation of semantically similar images without the need for actual text prompts. In addition, during training, we implement the TailDrop strategy, where the last k tokens are randomly dropped, encouraging earlier tokens in ViLex to carry richer semantic information. ViLex tokens can be utilized independently as “text” tokens for image generation or combined with natural language tokens for prompting T2I diffusion models with both visual and textual cues for multimodal image generation.
Experimental Outcomes and Key Insights from the Research
The findings demonstrated that ViLex significantly outperformed existing models regarding image reconstruction and understanding. The study indicated that even a single ViLex token achieved higher fidelity in image reconstruction than traditional text embeddings. Further evaluations revealed that the inception score (IS) of images generated by ViLex tokens reached 15.88, surpassing benchmarks set by models like DALL⋅E 3 and DeDiffusion. Notably, the novel model performed better in generating semantically and visually consistent images, achieving lower Fréchet Inception Distance (FID) scores than DALL⋅E 3 and DeDiffusion. Specifically, ViLex demonstrated an FID score of 2.07, showcasing its ability to generate semantically and visually coherent images.
In quantitative assessments, ViLex tokens enabled effective zero-shot unsupervised DreamBooth tasks without fine-tuning T2I models. This zero-shot capability allows ViLex to perform unsupervised multimodal image generation tasks without architectural modifications or additional training. Human evaluations further supported these results, with participants favoring images generated by ViLex over those produced by competing models in terms of layout, semantic accuracy, and artistic style. Furthermore, ViLex's integration into vision-language models, replacing traditional encoders, led to substantial performance enhancements across 15 benchmarks, demonstrating its versatility and robustness in various applications.
![ViLex retains more visual details in image-to-image generation compared to DALL·E 3 [5] and DeDiffusion [76], accurately capturing elements such as image style (e.g., the oil painting style in row 1), layout (e.g., the relative position of the corgi and the lighthouse), pose (e.g., the corgi’s stance), and object shapes (e.g., the shape of Van Gogh’s hat). This enables ViLex to produce images that are both semantically and visually consistent with the original input. Even models with text embeddings in a shared language-vision space, like DALL·E 3, capable of generating semantic variations of an image, struggle to faithfully reconstruct the original appearance of the input image. For image-guided DALL·E results, we provide the input images along with the text prompt, “generate an image exactly the same as the input image”. For DeDiffusion, we follow its official image-to-image generation pipeline and use SDXL [52] as the T2I model.](https://www.azoai.com/images/news/ImageForNews_5899_17345697549627889.png)
ViLex retains more visual details in image-to-image generation compared to DALL·E 3 [5] and DeDiffusion [76], accurately capturing elements such as image style (e.g., the oil painting style in row 1), layout (e.g., the relative position of the corgi and the lighthouse), pose (e.g., the corgi’s stance), and object shapes (e.g., the shape of Van Gogh’s hat). This enables ViLex to produce images that are both semantically and visually consistent with the original input. Even models with text embeddings in a shared language-vision space, like DALL·E 3, capable of generating semantic variations of an image, struggle to faithfully reconstruct the original appearance of the input image. For image-guided DALL·E results, we provide the input images along with the text prompt, “generate an image exactly the same as the input image”. For DeDiffusion, we follow its official image-to-image generation pipeline and use SDXL [52] as the T2I model.
Application of Newly Developed Model
The presented model has significant implications across various domains, including artificial intelligence (AI), computer vision, and human-computer interaction. Its ability to generate high-fidelity images from minimal input tokens positions ViLex as a powerful tool in creative industries, where image generation and manipulation are crucial.
Additionally, integrating ViLex with existing vision-language models can enhance their capabilities, making them more effective in interpreting and generating complex visual content. Its demonstrated improvements in vision-language tasks, such as image captioning and visual question answering, further highlight its potential in practical applications. Incorporating it into multimodal systems could revolutionize how individuals interact with visual data, enabling more expressive image-generation methods. As the model continues to evolve, it has potential in augmented reality, interactive media, and beyond.
Conclusion and Future Directions
In summary, the development of ViLex represents a significant advancement in image representation and understanding. Effectively encoding visual information into a text-based format enhances image generation capabilities and improves the performance of vision-language models. The findings highlighted models' potential to transform how individuals interact with visual content.
Future work should focus on further refining the ViLex model and exploring its scalability and adaptability to different types of visual content. Additionally, investigating the integration of ViLex with other emerging technologies, such as generative adversarial networks (GANs), could yield even more sophisticated image-generation capabilities. Expanding the use of ViLex for zero-shot tasks in real-world scenarios is another promising direction for exploration.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Wang, X., Zhou, X., Fathi, A., Darrell, T., & Schmid, C. (2024). Visual Lexicon: Rich Image Features in Language Space. ArXiv. https://arxiv.org/abs/2412.06774