While the importance of human vision is something we rarely question, few people are likely as confident in even recognizing the concept of computer vision. Like human vision, computer vision relates to how computers 'see.'
Specifically, computer vision refers to how computers recognize, identify, and analyze images and video. Computer vision is used in many sectors for its ability to monitor and analyze visual data in ways that extend past what human vision can do. This includes the medical, agricultural, and industrial sectors where, for example, early tumor detection, early pest detection, and fine quality control can save both money and, most importantly, lives.
For computer vision, one of the most challenging functions is camouflaged object detection (COD), which is the ability to recognize, identify, and analyze an object in an image or video that is difficult to differentiate from its background. In its initial stages, a cancerous cell may not look all that different from a healthy cell.
Since 2023, there has been a surge in COD research facilitated by deep learning, a type of machine learning. This field has seen the development of diverse strategies, including mechanism-simulation approaches inspired by nature and multi-task learning frameworks designed to leverage shared information across related tasks. This has created a large pool of research that has not yet been surveyed. To address this, a research group at Tsinghua University has undertaken an extensive review of the COD literature to catalog, review, and analyze the current state of the field.
Chunming He, a researcher at Duke University, is one of the paper's authors. He says the paper "provides the most comprehensive review to date on COD methods, emphasizing both theoretical frameworks and practical contributions. The survey covers advancements across image-level and video-level COD, examining traditional and deep learning approaches."
The review was published in the journal CAAI Artificial Intelligence Research. The research draws from around 150 studies to evaluate advancements and limitations in COD. The corresponding repository is available on GitHub at https://github.com/ChunmingHe/awesome-concealed-object-segmentation.
COD is used to analyze images and video footage. The two main streams of analysis fall under the traditional or newer deep learning categories. Traditional COD analyzes color, texture, and intensity data to separate and recognize hidden objects in visual images and video. However, the Tsinghua group noted that conventional computer vision is limited in many situations, including low-resolution images and instances where the object powerfully blends in with the background.
That is where deep learning comes in. Researchers needed a way to teach computers to recognize and analyze camouflaged objects in a broader range of conditions, with more flexibility and greater detail, without requiring human technicians to constantly label and sort the data. Deep learning uses a neural network that, in some ways, mimics the human neural network to allow a computer to learn and continue to learn by itself how to perform specific tasks such as COD.
Among the many approaches to using deep learning in COD that the researchers reviewed was the novel-task setting strategy approach. This includes unsupervised COD, which is critical for open-world scenarios where labeled data is unavailable, and collaborative COD, where multiple images of the same object class are analyzed for greater detection accuracy.
Novel task-setting strategies set the COD application to new tasks, allowing it to learn how to handle new situations and data to increase its abilities in novel and complex situations using several different methods.
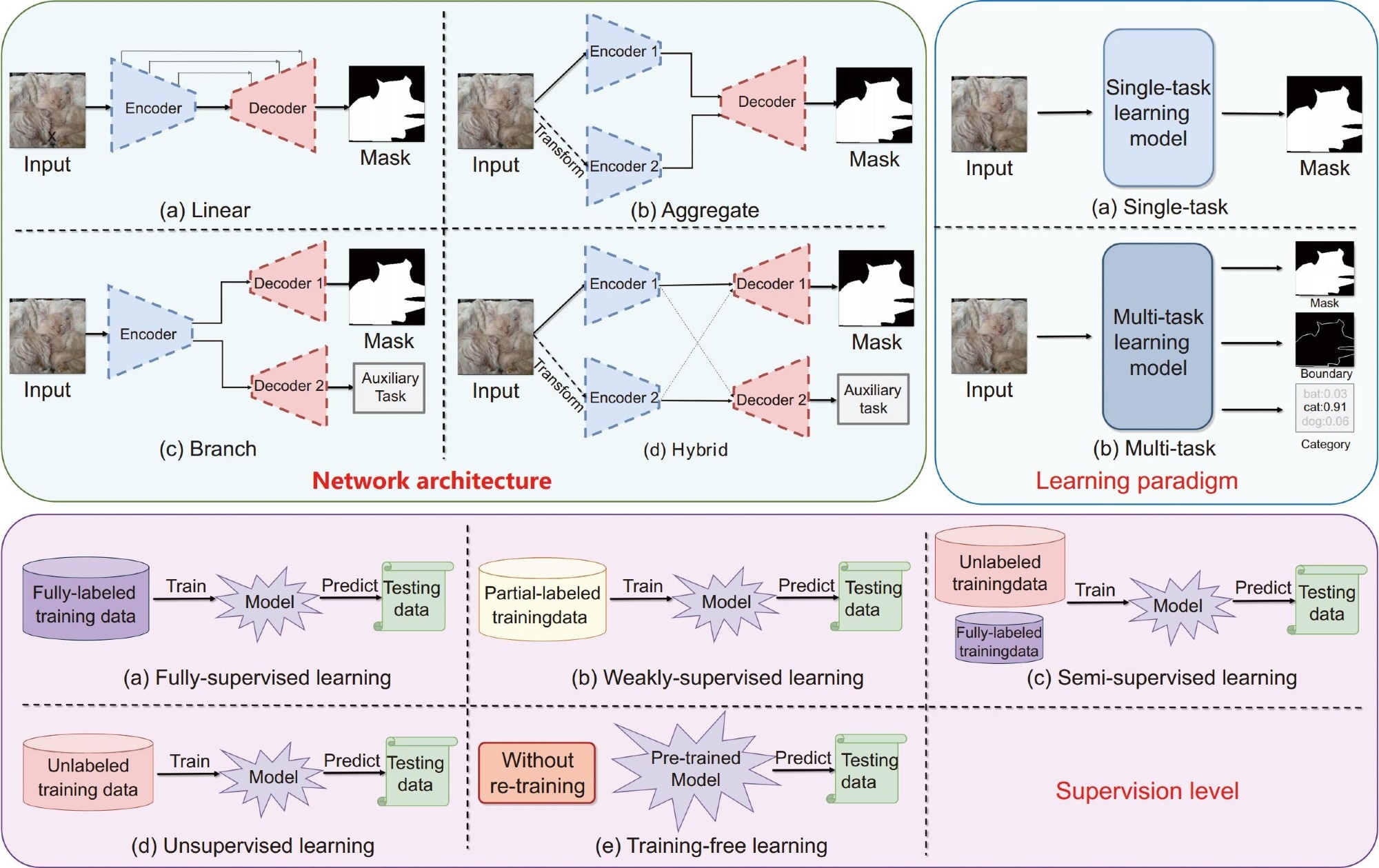
Three fundamental criteria, i.e., network architecture, learning paradigm, and supervision level, for deep learning COD methods. (1) Network architecture: the input and output configurations of models, including linear, aggregative, branch, and hybrid architectures. (2) Learning paradigm: the approach adopted by the models to learn, including single-task and multi-task paradigms. (3) Supervision level: the degree and nature of supervision provided during the training phase, including full-supervision, weak-supervision, semi-supervision, unsupervision, and training-free levels.
For example, referring-based COD can be used when a specific object is of interest. In that scenario, the target references, images, or text are introduced into the application so that it can learn to recognize the specific target and improve the overall performance of the application by increasing its exposure to more novel objects.
Collaborative COD does something very similar, but it introduces multiple images of an object or a class of objects so that the application can recognize a broader, more varied group of objects that still belong to one object class. Again, this increases the overall accuracy of the model. Both strategies take advantage of the strength of deep learning to refine, extend, and strengthen the applications' abilities to collect and analyze COD.
Despite its immense promise, several issues face the use of deep learning in COD. One issue is the scarcity of data that can be used to train these systems. 'To mitigate the scarcity of data, leveraging deep generative models to synthesize diverse, realistic camouflaged images will bolster training effectiveness by dataset augmentation, enhancing model robustness in dealing with camouflaged scenarios,' said Fengyang Xiao, first author and researcher at Tsinghua Shenzhen International Graduate School, Tsinghua University.
Looking forward, the next steps in COD research for He "involve addressing the identified limitations in COD methods by exploring innovative research directions, such as unsupervised and weakly supervised learning, multi-task and multi-modal approaches, and leveraging large-scale vision-language models. These efforts aim to enhance generalization to real-world data, tackle complex camouflage scenarios, and broaden COD’s applicability across domains like autonomous systems and wildlife conservation. The ultimate goal is to develop robust, efficient, and generalized COD models capable of tackling diverse and complex real-world scenarios, ensuring broader applicability and advancing the field of computer vision."
Other contributors, all from Tsinghua Shenzhen International Graduate School, Tsinghua University, include Sujie Hu, Yuqi Shen, Chengyu Fang, Longxiang Tang, Xiu Li, and Fengyang Xiao, all from the Department of Biomedical Engineering at Duke University; Jinfa Huang, from the School of Electrical and Computer Engineering at Peking University; and Ziyun Yang, also from the Department of Biomedical Engineering at Duke University.
Funding and Contributions. This work was supported by the STI 2030-Major Projects (No. 2021ZD0201404). The authors express their sincere appreciation to Dr. Deng-Ping Fan for his insightful comments, which significantly improved the quality of this paper.
Source:
Journal reference: