By adapting 2D foundation models for 3D tasks, researchers are unlocking new frontiers in spatial AI, enabling smarter robotics, enhanced scene understanding, and more efficient multimodal learning.
 Research: Foundational Models for 3D Point Clouds: A Survey and Outlook. Image Credit: ktsdesign / Shutterstock
Research: Foundational Models for 3D Point Clouds: A Survey and Outlook. Image Credit: ktsdesign / Shutterstock
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Understanding the three-dimensional (3D) world is a fundamental requirement for artificial intelligence (AI) systems to interact effectively with real-world environments. Among various 3D data formats, point clouds provide a high-fidelity representation of spatial information. They are widely used in computer vision, robotics, and augmented reality for tasks such as object recognition, scene understanding, and autonomous navigation. However, challenges such as high computational demands and the limited availability of labeled 3D datasets hinder progress in 3D learning.
Foundation models (FMs), initially developed for 2D vision and natural language processing (NLP), have demonstrated remarkable generalizability across various tasks. Recent research has explored extending these models to 3D domains, leveraging knowledge from 2D data. Despite significant advancements, a comprehensive review of 3D foundational models remains absent. A new paper posted to the arXiv preprint* server addresses that gap by summarizing state-of-the-art methods, categorizing their approaches, and identifying future research directions.
Background
Point clouds represent 3D objects as collections of points in space, capturing geometric details crucial for AI systems. They are commonly generated by LiDAR sensors, depth cameras, and photogrammetric methods. Unlike structured 2D images, point clouds are unordered and sparse, necessitating specialized learning techniques to extract meaningful features.
Developing robust AI models for 3D point clouds presents several challenges. Data scarcity is a primary concern since collecting and annotating large-scale 3D datasets is expensive and labor-intensive. Additionally, existing multimodal datasets that pair 3D data with text descriptions remain limited, making it difficult to leverage large-scale vision-language learning techniques. The computational overhead required for training deep-learning models on 3D data is significant, often limiting progress. Another issue is the lack of semantic information, as point clouds, unlike 2D images, do not inherently contain textures or detailed labels.
To address these challenges, researchers have turned to foundational models trained on multimodal datasets. These models integrate images, text, and point cloud data to enhance 3D understanding and enable effective learning without requiring vast labeled 3D datasets. Models such as ULIP and OpenShape align 3D objects with vision-language encoders like CLIP, bridging the gap between textual descriptions and spatial representations.
Building 3D Foundational Models
Foundational models for 3D tasks can be developed using three primary approaches. The first is direct adaptation, where pre-trained 2D models such as Vision Transformers (ViTs) and convolutional networks are repurposed for 3D tasks. Methods such as Image2Point and Pix4Point fall into this category, leveraging pre-trained 2D kernels and transforming them into 3D convolutions or tokenizing point cloud data for transformer-based models. Another example, PointCLIP, projects point clouds into 2D depth maps, allowing CLIP’s vision-language model to process them directly.
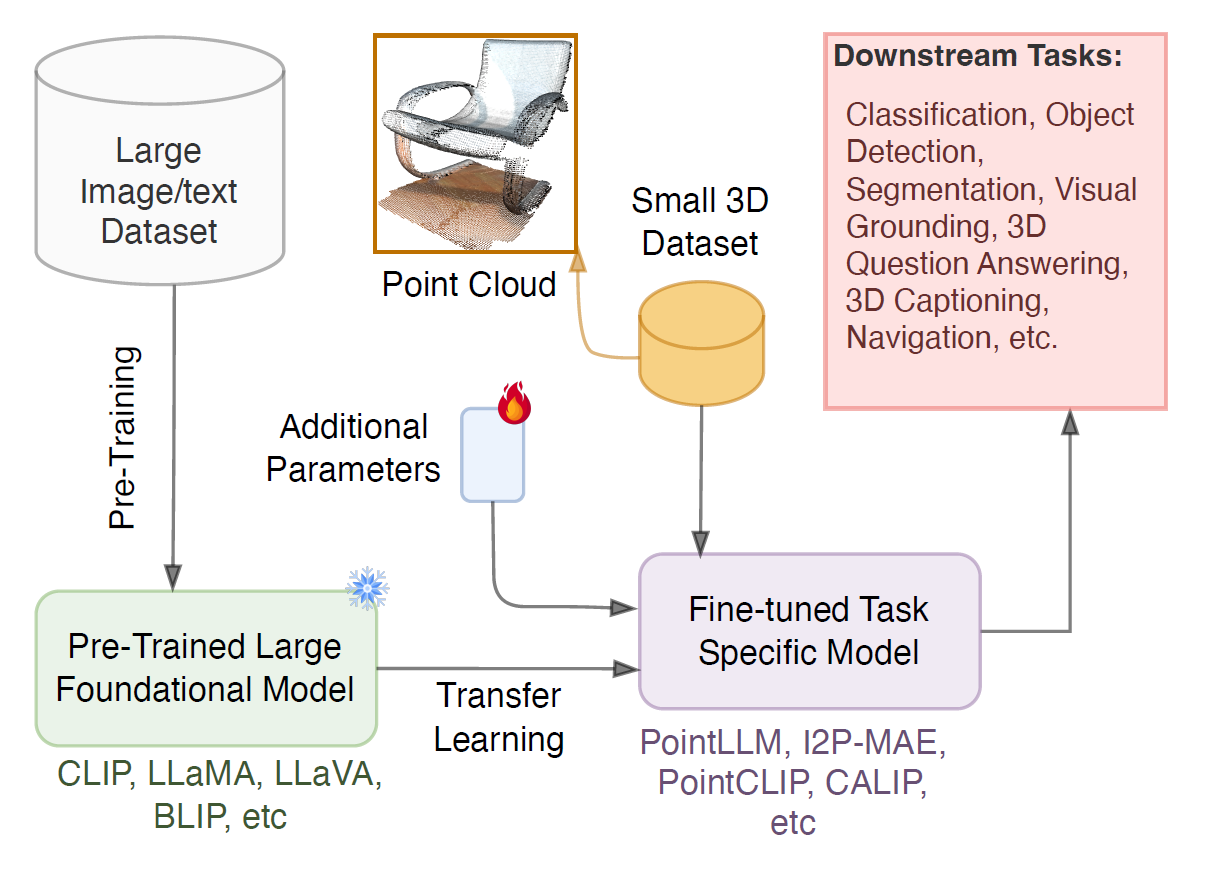
A general pipeline of using FMs for 3D vision tasks.
The second approach employs dual encoders, where separate encoders process 2D and 3D data, and their features are aligned using contrastive learning techniques. Examples include PPKT, which maps pixel- and point-level features into a shared space using noise contrastive estimation (NCE) loss. CLIP2Point follows a similar approach but aligns depth maps rendered from 3D point clouds with CLIP’s pre-trained image encoder. Bridge3D enhances 3D point cloud representations by integrating semantic masks and textual descriptions extracted from 2D foundation models such as Tag2Text, helping to improve cross-modal learning.
The third method, triplet alignment, integrates three modalities—images, text, and point clouds—using contrastive objectives to unify representations. Models such as ULIP and CG3D leverage CLIP’s encoders to bridge the gap between textual descriptions, image features, and point cloud structures. ULIP-2 further refines this approach by incorporating large vision-language models (VLMs) such as BLIP-2, generating more detailed text annotations for 3D data, which improves model alignment and generalization.
Adapting 2D Foundational Models for 3D Tasks
For 3D classification, several methods leverage foundational models for zero-shot and few-shot point cloud classification. CALIP uses cross-modal attention to align 3D point features with CLIP’s text embeddings. P2P applies vision prompting to project 3D data into color-enhanced 2D images for processing. Another approach, MvNet, uses multi-view image representations to improve few-shot learning performance. These methods effectively transfer knowledge from 2D vision models to 3D classification tasks. Performance comparisons show that ULIP achieves higher zero-shot classification accuracy than PointCLIP, demonstrating the effectiveness of triplet-aligned representations.
For 3D segmentation, recent efforts have extended 2D foundational models to segment 3D objects and scenes. SAM3D utilizes SAM (Segment Anything Model) to extract 2D masks from multi-view images and reconstruct them in 3D. ZeroPS combines GLIP and SAM for zero-shot 3D part segmentation, identifying object parts without explicit training. PartDistill distills knowledge from 2D foundational models into a student model trained for 3D part segmentation, enabling efficient adaptation of pre-trained models to new tasks. OpenMask3D and Open-YOLO3D further improve open-vocabulary segmentation by using pre-trained 2D models to generate instance masks, which are then projected into 3D space.
In open-vocabulary segmentation, 3D models generalize to unseen categories by leveraging large-scale vision-language models. These approaches fall into three main categories. Feature distillation transfers CLIP’s 2D embeddings to 3D models, as seen in OpenScene and CLIP-FO3D. Captioning-based methods generate pseudo-captioned 3D datasets for training, with PLA and RegionPLC being key examples. Newer methods, such as Open3DIS, improve instance segmentation by refining 2D object masks across multiple views before projecting them into 3D space, reducing misalignment errors. Another method, 3D projection, maps 2D mask proposals from SAM and CLIP onto 3D point clouds, as demonstrated in OpenMask3D and OVIR-3D.
Future Directions
Despite recent advancements, 3D foundational models face several limitations. The lack of large-scale, high-quality 3D-text paired datasets remains a significant hurdle for pre-training. While methods like ULIP-2 and OpenShape attempt to address this by synthesizing textual annotations from vision-language models, more extensive and diverse datasets are needed to improve scalability. Computational bottlenecks continue to hinder progress, necessitating more efficient training strategies such as parameter-efficient fine-tuning (PEFT). Generalization challenges must be addressed to improve cross-domain transferability, ensuring models perform well on unseen data. Scaling multimodal learning techniques, particularly those involving language-enhanced 3D representations could significantly improve model interpretability and reasoning capabilities.
Conclusion
This paper presents a comprehensive review of foundational models for 3D point clouds, categorizing methods based on their adaptation strategies and application domains. By leveraging 2D vision and language models, researchers have made significant progress in 3D understanding, but challenges remain in dataset availability, computational efficiency, and generalization. Emerging models such as Uni3D, which scale up 3D representation learning to billions of parameters and extensive multimodal datasets, represent a promising step forward. Future research should focus on scaling multimodal learning techniques to bridge the gap between 2D and 3D AI capabilities.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Thengane, V., Zhu, X., Bouzerdoum, S., Phung, S. L., & Li, Y. (2025). Foundational Models for 3D Point Clouds: A Survey and Outlook. ArXiv. https://arxiv.org/abs/2501.18594