MoE models have emerged as a promising solution that enables the activation of only a subset of specialized submodels during inference to improve efficiency without compromising performance. This architecture handles complex tasks more effectively by allowing the model to leverage expert knowledge in specific domains.
Despite their potential, few large-scale open-source MoE models have been developed, limiting their widespread use. This study aims to address this gap by introducing Hunyuan-Large, which not only scales MoE architectures but also improves performance through innovative techniques.
Hunyuan-Large: An Open-Source MoE Model
In this paper, the authors presented Hunyuan-Large, which combines classical Transformer architecture with a MoE design. During the pre-training phase, the model develops foundational capabilities. The post-training phase then refines task-specific skills to better align the model with human preferences.
The model was pre-trained on a dataset of 7 trillion tokens, including 1.5 trillion tokens of high-quality synthetic data. The tokenizer was optimized to include 128K tokens. This optimization balances compression rates and vocabulary size to enhance performance, particularly in supporting the Chinese language.
The model architecture comprises 64 layers, 80 attention heads, and a combination of shared and specialized experts. One key feature is the Key-Value (KV) cache compression, which reduces memory usage during inference by using grouped-query attention (GQA) and cross-layer attention (CLA). This method reduces cache size by nearly 95% compared to traditional methods, with minimal information loss during training.
The study also used a mixed expert routing strategy, where shared and specialized experts are activated based on a top-k scoring mechanism, ensuring efficient load balancing and optimal performance. Additionally, the model uses expert-specific learning rate scaling, applying different learning rates to each expert to improve training efficiency.
After pre-training, the model underwent supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). The researchers then evaluated Hunyuan-Large by benchmarking it against leading models, such as LLama3.1 (large language model by Meta AI version 3.1) and DeepSeek, across various tasks in both English and Chinese. They also compared it with dense and MoE models like LLama3.1-70B and LLama3.1-405B.
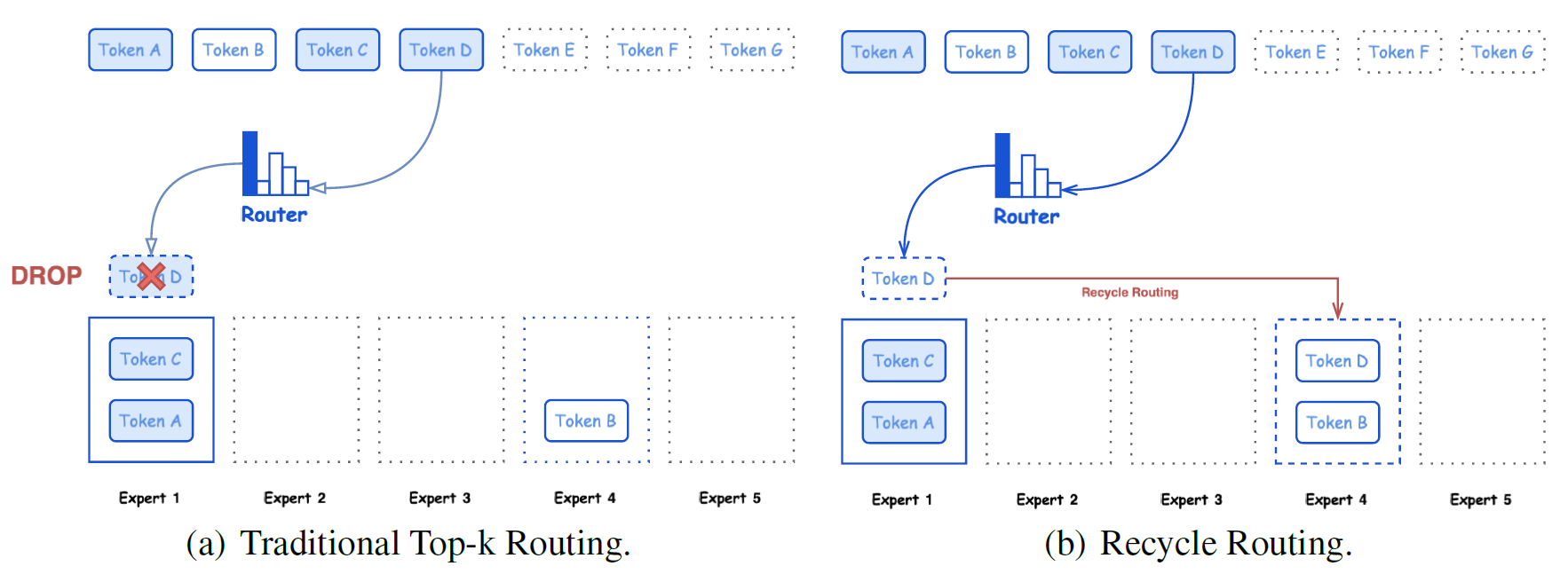
An illustration of the recycle routing strategy in Hunyuan-Large, where each expert’s maximum capacity is set to 2. Token D, which was initially allocated to the overloaded Expert 1, is reassigned to a randomly selected Expert 4. This approach helps alleviate the potential loss of valuable information. In traditional routing strategies, tokens from overloaded experts would be dropped as shown in (a). However, our strategy involves randomly reassigning these tokens to other experts, as demonstrated in (b), where Token D is routed to Expert 4.
Key Findings and Insights
The study showed that Hunyuan-Large outperformed existing models across various tasks. In comparative analyses, it demonstrated strong performance in common sense understanding, question answering, mathematical reasoning, and coding. Notably, despite using fewer activated parameters, the model surpassed LLama3.1-405B by 3.2% on massive multitask language understanding (MMLU) and grade school math 8K (GSM8K) benchmarks.
The authors also highlighted the model's proficiency in managing long-context tasks, with the ability to process sequences of up to 256K tokens. This feature is crucial for applications that require integrating large amounts of information and context, thereby broadening Hunyuan-Large’s potential for real-world use. Key factors behind the model's success include high-quality synthetic data used during pre-training, expert routing strategies, and training protocols developed through empirical testing.
Additionally, the researchers emphasized that combining high-quality synthetic data and innovative training strategies was essential in boosting the model’s performance. The use of synthetic data not only expanded the training dataset but also enabled the model to learn complex patterns more effectively.
Applications
This research has significant implications across various industries. In education, Hunyuan-Large can be used to develop intelligent tutoring systems for personalized learning. In software development, it can assist with code generation and debugging. Its strong reasoning and language understanding abilities make it suitable for customer support, content creation, and information retrieval tasks. Furthermore, the model’s open-source nature encourages collaboration and innovation within the AI community. The availability of its code enables further experimentation and adaptation to diverse use cases.
Conclusion and Future Directions
In conclusion, Hunyuan-Large represents a significant advancement in the field of LLMs. It proved effective in various tasks, including language understanding, generation, logical reasoning, mathematical problem-solving, coding, and long-context processing. As the demand for advanced AI systems grows, Hunyuan-Large offers significant potential for future research and applications, paving the way for intelligent systems capable of effectively processing and understanding complex information.
Future work should optimize the model's efficiency and performance by exploring new scaling laws and learning rate schedules for MoE models. Further advancements in domain-specific capabilities and techniques for handling larger datasets and more complex tasks would enhance the model’s potential.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Sources:
Journal reference:
- Preliminary scientific report.
Sun, X., & et al. Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent. arXiv, 2024, 2411, 02265. DOI: 10.48550/arXiv.2411.02265, https://arxiv.org/abs/2411.02265