The rapid increase in scientific publications makes it difficult for researchers to stay updated. Literature synthesis requires efficient retrieval, proper citation, and access to current information. Traditional methods, despite their widespread use, are often error-prone and particularly susceptible to inaccuracies in citation tracking and data retrieval.
While LLMs offer potential solutions, they often fabricate citations, rely on outdated data, and lack attribution methods. For instance, GPT-4o fabricated citations in 78-90% of cases in tests spanning computer science and biomedicine. RALMs address some of these issues by integrating external knowledge. However, many RALMs depend on black-box application programming interfaces (APIs) or general-purpose LLMs that are not optimized for scientific literature. Additionally, existing evaluations of literature synthesis tools are often narrow, focusing on single disciplines or simplified tasks.
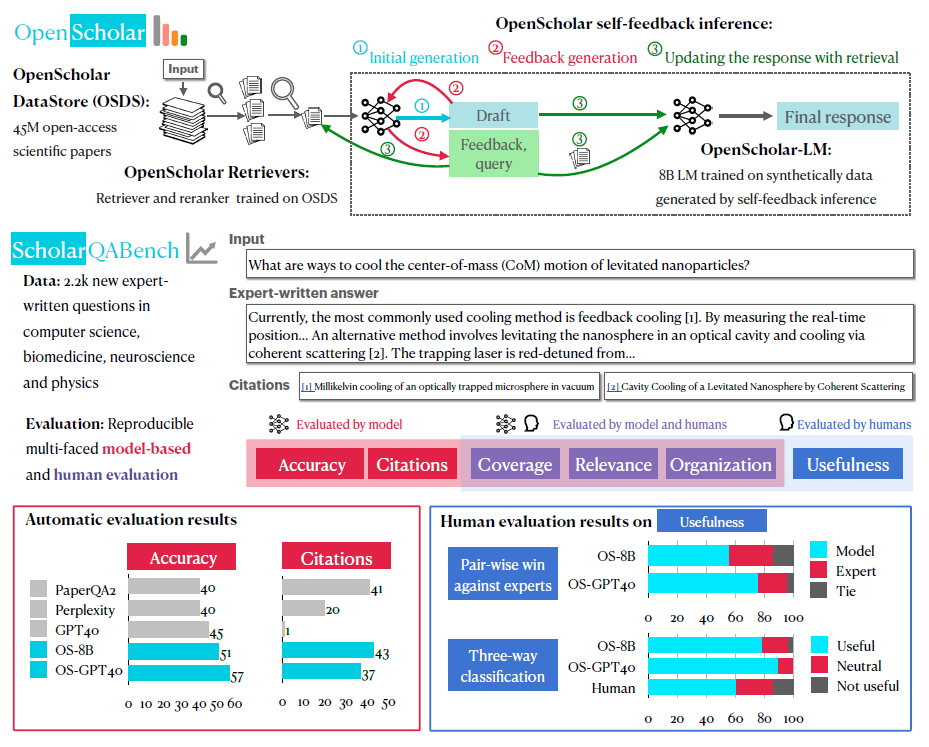
(Top) Overview of OPENSCHOLAR: OPENSCHOLAR consists of a specialized datastore, retrievers and LMs and iteratively improves responses using self-feedback inference with retrieval. (Middle) Overview of SCHOLARQABENCH: SCHOLARQABENCH consists of 2.2k expert-written questions across multiple scientific disciplines, and we introduce automatic and human evaluation protocols for SCHOLARQABENCH. (Bottom) Automatic and Human Evaluation Results: Experimental results show the effectiveness of SCHOLARQABENCH, and that OPENSCHOLAR with our trained 8B or GPT4o significantly outperforms other systems, and is preferred over experts over 50% of the time in human evaluations.
OpenScholar: An Open-Source RALM
In this paper, the authors introduced OpenScholar, a RALM designed to address the limitations of existing systems. OpenScholar includes several key components. It features an open-source datastore (OSDS) containing 45 million scientific papers. It also incorporates a retriever and reranker trained specifically on scientific data. Additionally, its flexible architecture supports both off-the-shelf LMs and the newly trained OpenScholar-LM.
A key innovation of OpenScholar is its self-feedback mechanism. This feature iteratively refines responses, allowing the model to identify missing content and incorporate supplementary retrieval steps, improving citation accuracy and the quality of generated outputs. The OSDS, built using peS2o v3 (Paper Embedding Semantic Scholar Open Research Corpus version 3), contains 234 million passages from papers published up to October 2024. For evaluation, peS2o v2 (data up to January 2023) was used.
OpenScholar employs a three-step retrieval pipeline. First, a bi-encoder retrieves relevant passages. Second, keyword-based searches use the Semantic Scholar API. Finally, academic searches are conducted through You.com API, focusing on educational platforms.
Following the retrieval phase, the language model generates responses that include citations linked to the original literature, enhancing transparency and verifiability. This iterative process continues until the system verifies that all claims in the generated output are properly supported by the retrieved sources. The iterative self-feedback mechanism allows OpenScholar to refine its outputs, address information gaps, and improve overall quality.
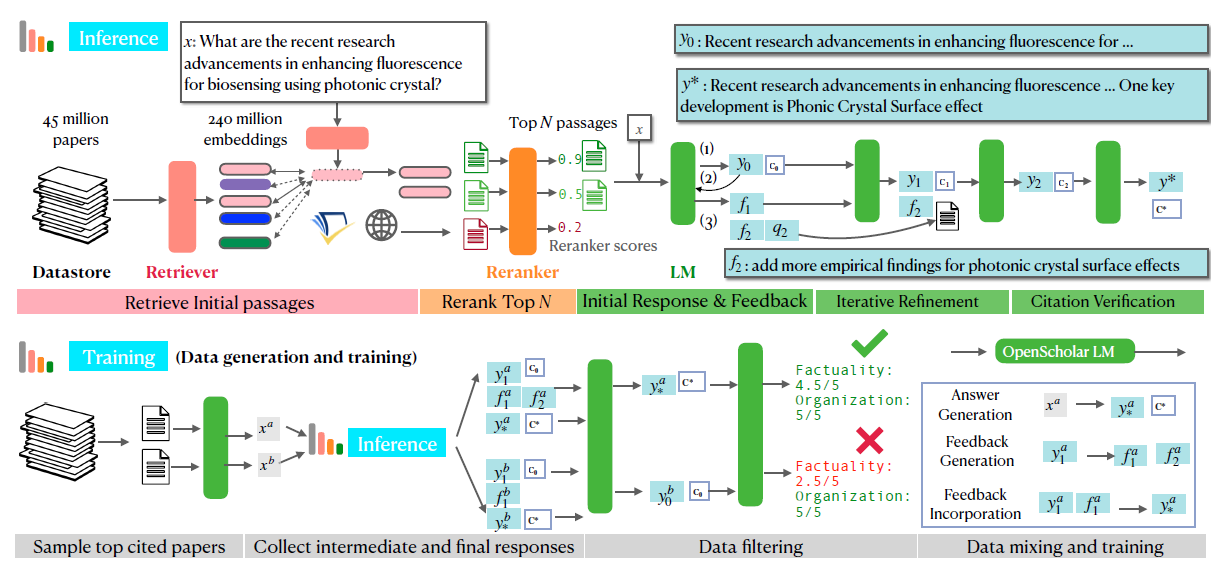
Detailed overview of OPENSCHOLAR inference (top) and training (bottom). At inference time, given an input x, OPENSCHOLAR first uses a retriever to identify relevant papers from a specialized datastore (OPENSCHOLAR-Datastore), and then uses a reranker to refine and identify the top N retrieved documents. The retrieved output is then passed to the LM, which generates both an (1) initial response y0 and (2) self-feedback f1. By incorporating its own feedback, the LM iteratively refines its output a pre-defined number of times. Subsequently, an LM (1) generates initial response y0, (2) generates self-feedback on the initial output, and (3) incorporate feedback (fi) to generates an updated response y1. The LM repeats the process until all feedback is incorporated. To train a smaller yet competitive 8B LM, we generate high-quality training data using this inference-time pipeline followed by data filtering and mixing.
Evaluation and Performance of OpenScholar
The researchers developed ScholarQABench, a benchmark dataset comprising 2,967 literature synthesis questions and 208 expert-written long-form responses spanning four scientific disciplines (computer science, physics, biomedicine, and neuroscience). Each response required approximately one hour to craft and was authored by researchers with at least three years of domain expertise. This benchmark serves as a comprehensive evaluation framework for testing the capabilities of OpenScholar and other LLMs in accurately retrieving and synthesizing relevant scientific literature.
The study also includes a detailed evaluation of OpenScholar's performance compared to existing models, such as GPT-4o and PaperQA2, showing that OpenScholar achieved a 5% improvement over GPT-4o and a 7% improvement over PaperQA2 in correctness.
Key Outcomes and Insights
The findings indicated that OpenScholar significantly outperformed existing LLMs in various aspects of literature synthesis. On the ScholarQABench benchmark, OpenScholar-8B achieved a 5% improvement over GPT-4o and a 7% improvement over PaperQA2 in terms of correctness. Notably, while GPT-4o exhibited a high rate of hallucination in citations (78-90%), OpenScholar demonstrated citation accuracy comparable to that of human experts.
Human evaluations further corroborated these findings, with experts preferring the responses generated by OpenScholar-8B and OpenScholar-GPT4o over expert-written answers 51% and 70% of the time, respectively. This highlights the model's ability to produce comprehensive, well-organized responses that effectively synthesize information from multiple sources. Additionally, integrating OpenScholar with existing LLMs, such as GPT-4o, resulted in a 12% improvement in correctness, showcasing its potential to enhance off-the-shelf LLMs.
The study also emphasized the importance of citation accuracy in scientific literature synthesis. OpenScholar's ability to provide accurate citations not only enhances the credibility of the generated responses but also facilitates researchers' ability to trace information back to its original sources, fostering a more reliable scientific discourse.
Applications
This research has significant potential for scientists and researchers involved in literature reviews. OpenScholar provides a powerful tool for synthesizing information from diverse sources, streamlining the literature review process. Its capability to generate citation-backed responses enhances information reliability, making it an essential resource for those needing accurate and timely data to support their work.
Additionally, OpenScholar's open-source nature promotes widespread adoption and ongoing development within the scientific community. By providing access to its model, code, and data, the authors encourage collaboration and innovation, paving the way for future advancements in literature synthesis technologies.
Conclusion and Future Directions
In conclusion, OpenScholar demonstrated effectiveness in synthesizing scientific literature. The findings highlighted their superiority in correctness and citation accuracy compared to existing models, addressing key challenges researchers face when navigating vast scientific knowledge. OpenScholar not only enhances the reliability of literature reviews but also sets a foundation for future improvements in automated literature synthesis.
Future work should focus on refining retrieval mechanisms, expanding datasets to cover more disciplines, and incorporating adaptive user interfaces and feedback loops. Such enhancements will likely improve OpenScholar's usability and extend its capabilities for real-world research applications.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Sources:
Journal reference:
- Preliminary scientific report.
Asai, A., He, J., Shao, R., Shi, W., Singh, A., Chang, J. C., Lo, K., Soldaini, L., Feldman, S., Wadden, D., Latzke, M., Tian, M., Ji, P., Liu, S., Tong, H., Wu, B., Xiong, Y., Zettlemoyer, L., Neubig, G., . . . Hajishirzi, H. (2024). OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs. ArXiv. https://arxiv.org/abs/2411.14199