Advancement in Artificial Intelligence Technologies
Artificial Intelligence (AI) techniques, particularly LLMs, have revolutionized document creation, email drafting, and presentation generation. Their integration into platforms such as Microsoft 365 and Google Workspace has significantly enhanced productivity, allowing users to generate and process content more efficiently. Recent advancements have also introduced LLMs into multi-agent frameworks, where the output of one model becomes the input for another, further improving the quality and relevance of generated content.
However, the growing complexity of these models highlights the need for robust evaluation mechanisms to ensure the quality and appropriateness of their outputs. Traditional metrics like bilingual evaluation understudy (BLEU) and recall-oriented understudy for gisting evaluation (ROUGE) depend on well-defined reference texts, limiting their effectiveness in real-world scenarios where such references are unavailable. This gap highlights the need for innovative evaluation frameworks capable of operating effectively in reference-free contexts.
SAGEval: Framework for Evaluating LLMs Outputs
In this paper, the authors presented SAGEval, a novel technique designed to overcome the limitations of conventional evaluation methods for assessing open-ended, reference-free texts generated by LLMs. Their framework features a dual-agent system comprising an Evaluator Agent and a SAGE Agent. The Evaluator Agent initially assigns scores for the generated text across eight predefined scoring criteria, including accuracy, semantic diversity, and audience engagement, among others. The SAGE Agent critiques these scores, offering feedback, suggesting refinements, and even proposing new scoring dimensions such as creativity and content quality. This iterative approach enhances the accuracy of evaluations and addresses gaps in predefined criteria.
The study utilized a dataset of 96 surveys and forms generated by GPT-3.5-Turbo using concise prompts of up to 50 words. Human annotators, including experienced linguists familiar with AI, provided qualitative assessments of the outputs based on accuracy, coherence, and audience engagement. These human annotations served as a benchmark to evaluate the performance of the SAGEval framework.
To validate its effectiveness, the researchers conducted a comparative analysis of SAGEval against existing evaluation methods, including generalized evaluation (G-Eval) and free evaluation (FreeEval). Using Spearman and Kendall-Tau correlation metrics, they demonstrated that SAGEval aligns closely with human annotations, effectively capturing the nuances of natural language generation outputs.
Key Findings: The Impact of SAGEval
The study demonstrated the effectiveness of the SAGEval framework in evaluating open-ended, reference-free texts. A key outcome was the ability of the SAGE Agent to adjust scores assigned by the Evaluator Agent, resulting in more accurate and nuanced assessments of content quality. For example, the SAGE Agent frequently identified inflated scores, with approximately 92% of its adjustments being negative. This stricter evaluation approach led to better alignment with human judgments.
Audience engagement emerged as the most frequent area of disagreement, with the SAGE Agent suggesting lower scores in 76 of 96 cases. This highlights the need for more nuanced scoring criteria in this category. Additionally, the SAGE Agent proposed new scoring aspects, such as creativity and content quality, to broaden the evaluation scope and better capture the dynamic nature of open-ended text.
Correlation analysis further validated SAGEval's effectiveness. The framework outperformed existing methods like G-Eval and FreeEval, achieving correlation scores approximately 20% higher than conventional techniques in areas such as accuracy and audience understanding. The audience engagement dimension, however, continued to receive notably lower scores from human annotators, indicating room for improvement in the predefined criteria.
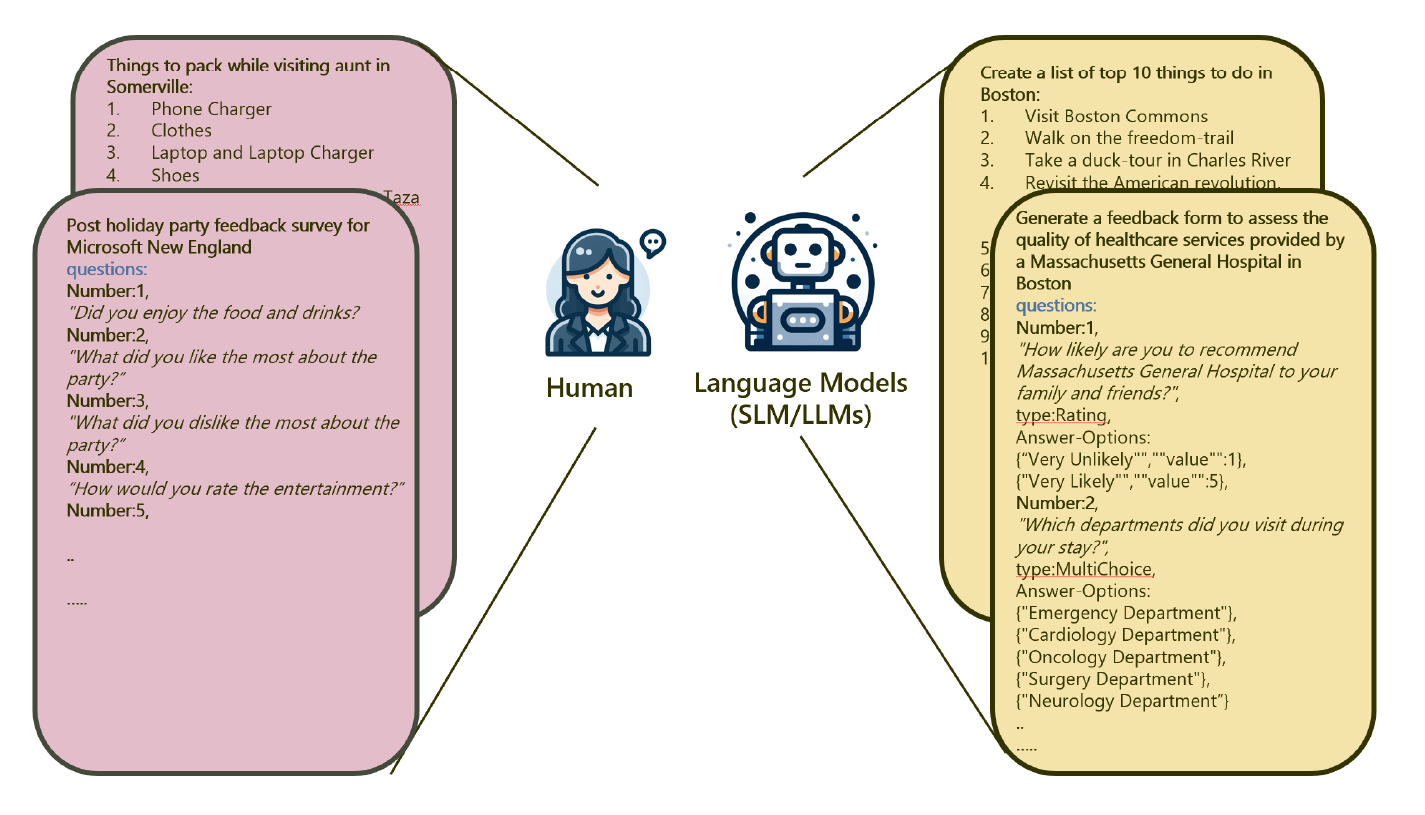
Open-ended human-drafted and NLG texts like lists, surveys, forms, contains sub-items or entities that are associated with a central theme such as "List of things to pack while traveling", or "Survey on assessing the quality of healthcare services", but these items (bullets in a list, questions in a survey) differ from each other, and it is important to make sure that the variance in open-ended text is coherent and aligned to the central theme.
Applications for Transforming NLG Evaluation
The SAGEval framework has implications across various domains utilizing LLMs. By offering a robust mechanism for evaluating open-ended texts, it enhances quality assurance in applications such as automated survey generation, content creation tools, and interactive AI systems. This ensures that outputs are coherent, relevant, and trustworthy, fostering user confidence in AI-generated content. It can be valuable in sectors like education, marketing, and customer service, where high-quality and engaging content is critical.
Furthermore, integrating a critiquing agent introduces a dynamic element to the evaluation process, enabling continuous refinement of scoring criteria and LLM performance. By adapting to user feedback and evolving language trends, the framework supports improved accuracy and relevance in natural language generation, thereby improving the user experience.
Conclusion and Future Directions
In summary, the SAGEval framework represents a significant advancement in evaluating natural language generation, especially in reference-free scenarios. Utilizing role-based LLM agents effectively addressed the limitations of conventional evaluation methods, enabling a comprehensive assessment of text quality. The study's findings validated the framework's effectiveness and highlighted its potential for applications in AI-driven content creation.
However, the framework currently focuses on structured formats like surveys and forms. Future research could expand SAGEval's capabilities to evaluate unstructured data formats, such as dialogues or narratives. This would enhance its versatility and foster advancements in natural language understanding and generation technologies.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Ghosh, R., Yao, T., Chen, L., Hasan, S., Chen, T., Bernal, D., Jiao, H., & Hossain, H. M. (2024). SAGEval: The frontiers of Satisfactory Agent based NLG Evaluation for reference-free open-ended text. ArXiv. https://arxiv.org/abs/2411.16077