In an article recently submitted to the arXiv preprint server, researchers highlighted the significance of honesty in large language models (LLMs) as a key factor for aligning with human values. They noted that current LLMs often display dishonest behaviors, such as confidently providing incorrect answers or failing to express the knowledge they actually possess.
The authors also addressed challenges in defining honesty and distinguishing between known and unknown knowledge. Their survey covered evaluation methods for assessing honesty and improvement strategies while offering insights for future research in this important area.
The article emphasized honesty in LLMs by describing two critical aspects: self-knowledge and self-expression. Self-knowledge refers to an LLM's awareness of its capabilities, allowing it to acknowledge limitations and express uncertainty. This concept is key to preventing models from misleading users. Self-expression involves the accurate and faithful conveyance of knowledge, which is crucial for reliable outputs. The authors noted that challenges in achieving both self-knowledge and self-expression lead to hallucinations and inconsistencies, highlighting their importance in LLM development.**
LLM Honesty Evaluation
Previous research on honesty in LLMs has been consolidated into two main categories: self-knowledge and self-expression. Self-knowledge refers to an LLM's ability to recognize its strengths and limitations, with evaluation conducted through two primary approaches: a binary judgment of known versus unknown and continuous confidence scoring. The binary approach assesses whether LLMs can recognize known and unknown information, while the confidence-based method involves assigning confidence levels to responses and evaluating aspects such as calibration and selective prediction.
The approaches can be categorized as model-agnostic, which uses identical evaluation questions across models, or model-specific, tailored benchmarks that evaluate individual models. Examples of model-agnostic benchmarks include SelfAware and UnknownBench, which typically use questions from curated datasets and classify them as known or unknown based on the model's training data. In contrast, model-specific benchmarks like the Idk (I don't know) benchmark rely on the model's performance to determine known versus unknown status.
Evaluation metrics include the F1 score and refusal rate. The F1 score assesses the model's accuracy in distinguishing known and unknown responses, while the refusal rate measures how effectively the model declines to answer questions it lacks knowledge about. Calibration ensures that the confidence scores reflect the actual likelihood of a correct answer, which is evaluated using the Brier score and expected calibration error (ECE).
Selective prediction evaluates how well confidence scores differentiate between correct and incorrect predictions, using metrics like the Area Under the Receiver Operating Characteristic Curve (AUROC), the Area Under the Precision-Recall Curve (AUPRC), and the Area Under the Average Receiver Characteristic Curve (AUARC) to assess the model's performance in this regard.
The current research landscape indicates a need to further explore the impact of honesty in long-form instruction-following scenarios that have not been as thoroughly investigated.
Challenges in Self-Expression
Self-expression relates to how well LLMs can convey their knowledge accurately. It is evaluated through both identification-based and identification-free approaches. The identification-based evaluation assesses whether an LLM can accurately express the correct answer based on the identified knowledge, often using benchmarks like those employed in self-knowledge evaluation.
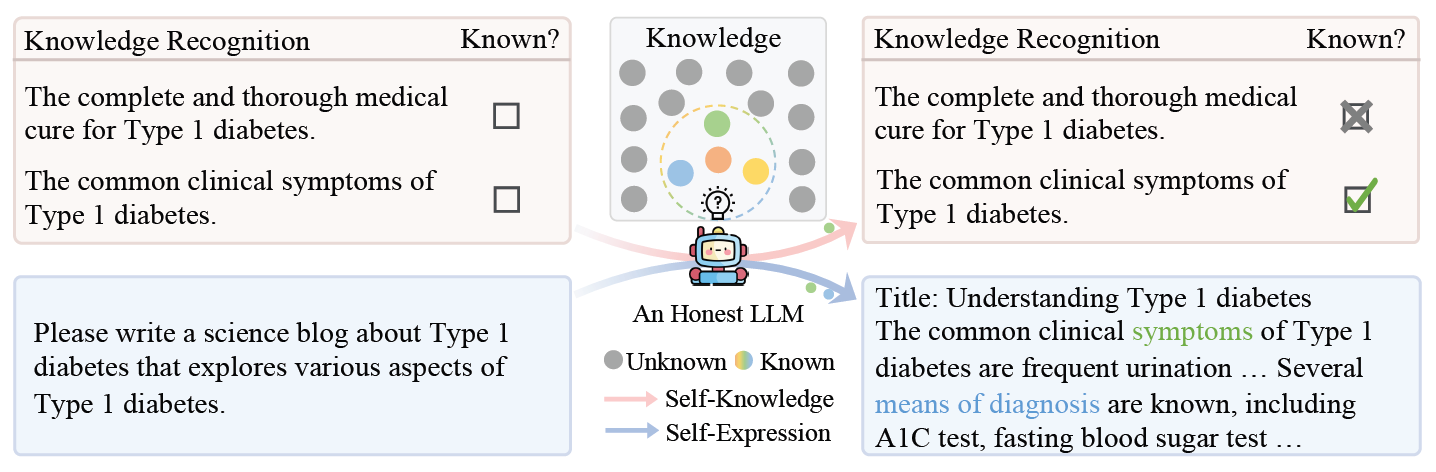 An illustration of an honest LLM that demonstrates both self-knowledge and self-expression.
An illustration of an honest LLM that demonstrates both self-knowledge and self-expression.
Conversely, the identification-free approach focuses on the consistency of outputs across different prompts referencing the same expertise. While current evaluations predominantly focus on short-form question answering, the expansion of evaluations to include long-form instruction scenarios could reveal more about LLM capabilities and limitations in self-expression.
Evaluating and Improving LLM Integrity
Research on honesty in LLMs has focused on two key aspects: self-knowledge and self-expression. Self-knowledge evaluates an LLM's ability to recognize its strengths and limitations through binary judgment and continuous confidence scoring. Evaluation methods can be model-agnostic or model-specific, with benchmarks like SelfAware and Idk providing a framework for assessing how well LLMs manage known and unknown knowledge.
Advanced evaluation metrics, such as the F1 score, refusal rate, and calibration metrics, help assess an LLM’s accuracy and confidence in predictions. Self-expression examines how well LLMs can accurately convey knowledge, highlighting the need for further research into long-form instruction scenarios to better understand their capabilities and limitations.
Enhancing LLM Knowledge Expression
Investigations into enhancing the knowledge expression abilities of LLMs have primarily centered around two key strategies: training-free and training-based approaches. Training-free approaches include techniques such as chain-of-thought prompting and decoding-time interventions that unlock internal knowledge during generation. Aggregation methods, such as sampling multiple outputs to generate consistent answers, are also used to improve output reliability.
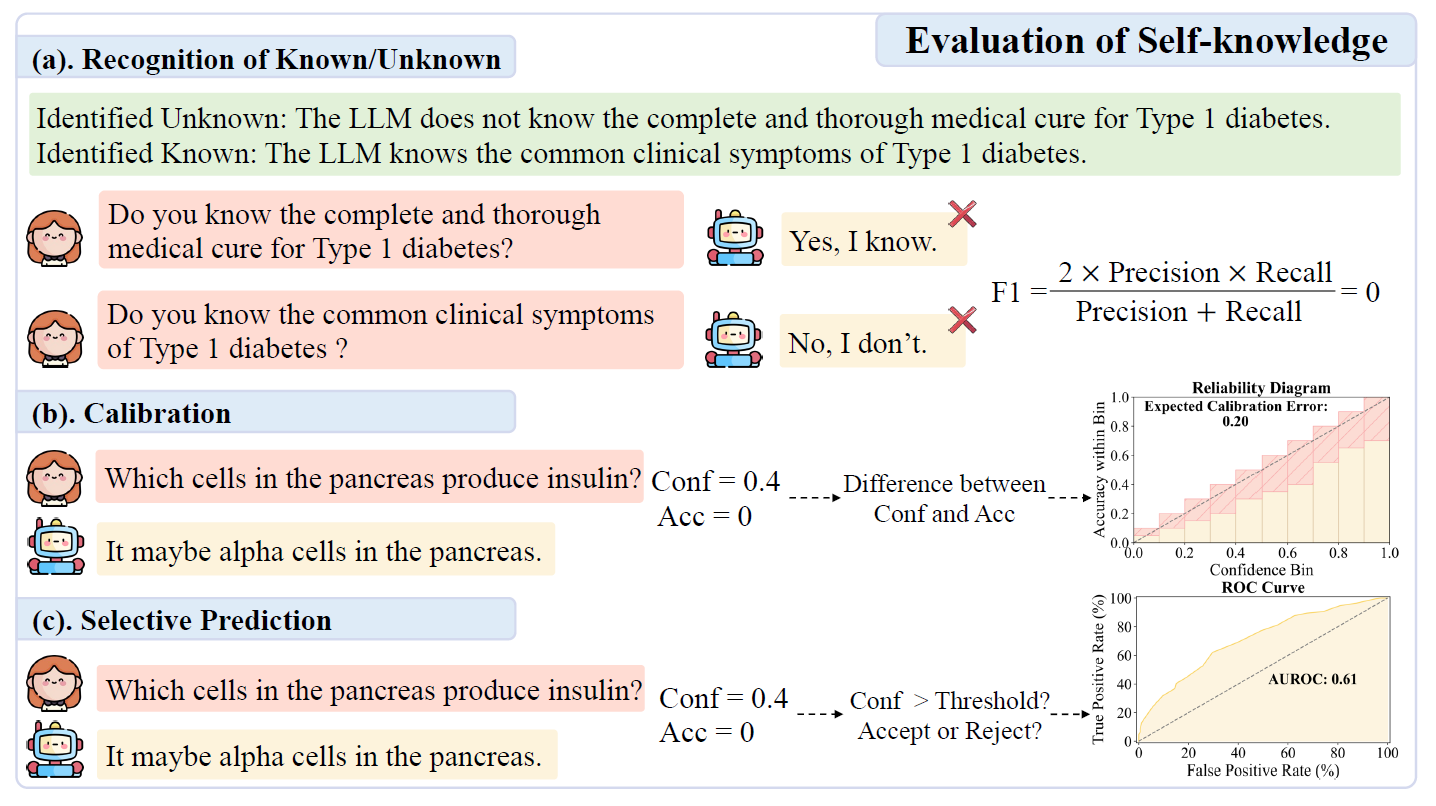 Illustrations of self-knowledge evaluation encompassing the recognition of known/unknown, calibration, and selective prediction. “Conf” indicates the LLM’s confidence score and “Acc” represents the accuracy of the response.
Illustrations of self-knowledge evaluation encompassing the recognition of known/unknown, calibration, and selective prediction. “Conf” indicates the LLM’s confidence score and “Acc” represents the accuracy of the response.
Training-based approaches emphasize self-aware fine-tuning, which encourages models to acknowledge knowledge limits, and self-supervised fine-tuning that utilizes internal knowledge for optimization. However, despite improvements, significant challenges remain in ensuring the reliability and accuracy of outputs. Ongoing research seeks to refine these methods for better performance.
Conclusion
To sum up, honesty was recognized as a critical factor in developing LLMs, although significant dishonest behaviors persisted in current models. The paper provided a comprehensive overview of research on LLM honesty, covering clarifications on the concept of honesty, detailed evaluation methods, and strategies for improvement. It also proposed several potential directions for future research. The authors hoped this survey would serve as a valuable resource for teams studying LLM honesty and inspire further exploration in the field.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Li, S., et al. (2024). A Survey on the Honesty of Large Language Models. arXiv, DOI: 10.48550/arXiv.2409.18786, https://arxiv.org/abs/2409.18786