In a paper published in the journal Sensors, researchers highlighted the critical role of virtualization in enhancing the virtual reality (VR) user experience, especially in indoor environments, by offering heightened realism and increased immersion. Conventional content generation techniques required a unified approach because they were either labor-intensive or complicated and semi-automated.
The team developed the virtual experience toolkit (VET), an automated framework utilizing deep learning (DL) and advanced computer vision (CV) techniques, to address these challenges. VET included Unity3D, a completely automated program for building interactive 3D environments, and ScanNotate, an enhanced tool for improved accuracy and efficiency. A variety of datasets were used to illustrate the efficacy of VET.
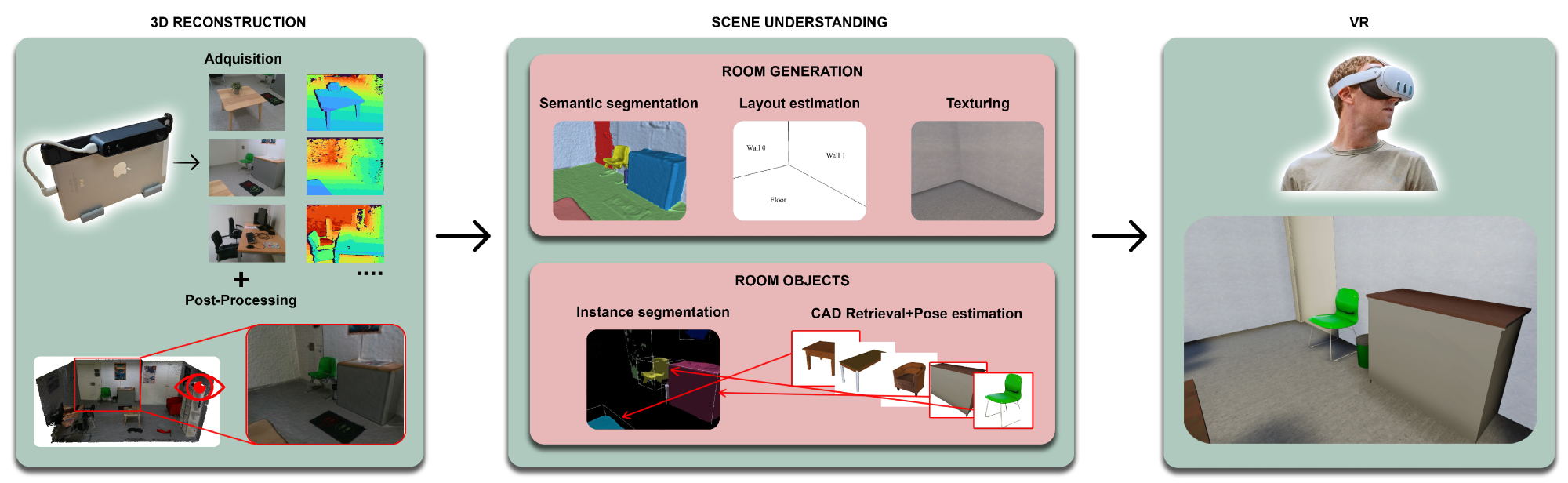 Pipeline followed by VET framework.
Pipeline followed by VET framework.
Background
In previous works, 3D scene virtualization has gained widespread attention due to the growth of VR and increased automation in indoor scenarios. Early 3D virtualization methods were manual and time-consuming. Recent advancements include various approaches to 3D reconstruction, scene understanding, computer-aided design (CAD) retrieval, and pose estimation.
For 3D reconstruction, conventional photogrammetry and more recent techniques, such as neural radiance fields (NeRF), are employed, while DL algorithms have increased scene interpretation. For enhanced object detection, instance segmentation extensively uses convolutional neural networks (CNNs). Finally, CAD retrieval and pose estimation enhance scene interactivity, and texture synthesis improves realism by generating high-quality textures from sample images.
3D Scene Virtualization Framework
VET achieves 3D virtualization of real indoor scenes through several stages encapsulated in a Unity3D application. The process begins with 3D reconstruction using red, green, and blue with depth (RGB-D) imagery and BundleFusion. This advanced simultaneous localization and mapping (SLAM) technique ensures high-fidelity 3D models by optimizing camera trajectories and refining surfels for structural coherence. Post-reconstruction refinement reduces polygon counts and aligns the reconstructed scene with the ScanNet dataset's coordinate system.
Following reconstruction, the framework employs semantic segmentation and layout estimation. Using octree representation, octree-based CNN (O-CNN) semantically segments the 3D environment into distinct regions, such as furniture and room parts. A novel robust statistics-based plane detection (RSPD) method detects planes and computes their intersections to estimate room layouts, carefully handling parallel and duplicated planes to ensure accuracy. Mask3D uses a sparse convolutional backbone to achieve instance segmentation. Transformer decoders segment specific objects in the scene accurately and efficiently.
The final steps involve CAD retrieval and alignment, replacing segmented objects with CAD models using the ScanNotate method. It includes preprocessing steps to calculate 3D bounding boxes and select representative images, followed by a fast mode that preselects CAD models based on the cosine similarity of 3D embeddings. The scene's realism is enhanced by adding plane textures, using the Plan2Scene module to generate textures from image crops, ensuring seamless integration with the original environment.
VET Framework Evaluation
A curated dataset from Universitat Politècnica de València (UPV) was specifically compiled to evaluate the VET framework's performance across diverse indoor environments. This dataset encompasses 30 unique scenes, including a demo room, for a thorough evaluation.
Comprehensive results across its distinct stages are presented to evaluate VET's efficacy qualitatively. The process initiates with real-time room scanning using BundleFusion, enabling users to visualize ongoing reconstructions and identify areas that require additional scanning. Following this, a refined reconstruction method enhances the scene's quality, reducing artifacts and enhancing detail, as demonstrated in comparative visualizations. These stages lay the foundation for subsequent tasks such as semantic segmentation, layout estimation, and instance segmentation, each contributing to the framework's ability to delineate scene components and objects accurately.
 Examples of an edited object using the custom GUI of VET. (a) Translated and rotated object. (b) Scaled object.
Examples of an edited object using the custom GUI of VET. (a) Translated and rotated object. (b) Scaled object.
When assessing VET's performance, high accuracy is found in identifying specific objects and architectural features inside scenes, especially in semantic segmentation using an O-CNN and instance segmentation with mask3D. Notably, VET significantly improves texture generation and layout extraction, two critical tasks for creating lifelike scenes for virtual reality applications. VET improves scene quality by substituting segmented items with appropriate CAD models and incorporating CAD retrieval and alignment features. It enables immersive experiences customized to meet individual user requirements.
Overall, VET represents a robust solution for 3D scene virtualization, supported by a rigorous evaluation framework and a commitment to open accessibility through the UPV dataset. It exemplifies advancements in scene reconstruction technology, with potential applications ranging from clinical scenarios in VR-based therapies to practical uses in home renovation and real estate visualization. Despite inherent limitations in handling dynamic environments and certain object types, VET's capabilities underscore its transformative potential in various domains requiring detailed, interactive 3D modeling and visualization.
Conclusion
In summary, VET was a pioneering framework that automated the complete virtualization of 3D scenes using advanced CV and DL techniques evaluated through specialized datasets. It demonstrated versatility in handling various indoor scenes and supporting up to 200 object classes, incorporating state-of-the-art methods across its pipeline to achieve highly accurate 3D scene virtualizations.
Plans included enhancing mask3D's wall and floor segmentation capabilities, expanding the CAD model dataset to include industrial and sanitary objects, and potentially integrating scene illumination annotation during acquisition. The framework aimed to extend its applicability to outdoor VR applications and undergo usability testing to confirm its user-friendly design claims, with deployment in real-world scenarios from the EXPERIENCE project to validate its practical utility for non-expert users.
 Deep Learning Maps Rising Urban Heat Stress and Warns of Future Risks
Deep Learning Maps Rising Urban Heat Stress and Warns of Future Risks