LLMs are advanced artificial intelligence (AI) systems that can understand and generate human-like language and responses. Trained on large amounts of text data, they have shown remarkable capabilities in natural language processing tasks such as language translation, content creation, summarization, and answering questions.
These models, such as those developed by OpenAI and other leading AI organizations, have also demonstrated potential in complex reasoning tasks, especially in coding and mathematics. However, whether LLMs can truly perform logical reasoning remains a key question. Researchers have observed that these models often rely on token-based pattern-matching rather than formal reasoning. Previous research has suggested that LLMs often rely on probabilistic pattern-matching rather than genuine reasoning, raising concerns about their reliability in complex scenarios. This study aims to provide deeper insights into the strengths and weaknesses of LLMs in mathematical tasks.
GSM-Symbolic: A Novel Benchmark
This paper investigated the mathematical reasoning capabilities of LLMs using the GSM8K benchmark, which includes over 8,000 grade-school math problems designed to test arithmetic and logical skills. However, their static nature only provides a single metric on a fixed set of questions, limiting the insights into reasoning abilities.
To address these limitations, the authors introduced GSM-Symbolic, a novel benchmark that uses symbolic templates to generate different question sets. This approach allows more controlled evaluations, providing a clearer view of LLMs' reasoning abilities. Specifically, GSM-Symbolic enables experiments where variables like numbers, names, and clauses can be modified to test the models’ true reasoning capabilities.
The researchers evaluated 25 state-of-the-art open and closed models by analyzing their performance on variations of the same questions under different conditions. They analyzed the fragility of LLMs’ reasoning capabilities by observing how performance changes when numerical values and the number of clauses in the questions were modified.
Around 500 evaluations were performed, with 100 templates generating 50 samples each, resulting in 5,000 examples per benchmark. Chain-of-thought (CoT) prompting and greedy decoding were used for these evaluations. The study also assessed the impact of changing numerical values, proper names, and the number of clauses on model performance.
Key Findings and Insights
The outcomes showed significant performance variations across all models when responding to different versions of the same question. In particular, performance dropped when only the numerical values were changed in the GSM-Symbolic benchmark. This suggests that existing LLMs do not engage in genuine logical reasoning but instead replicate reasoning patterns from their training data due to token bias.
Additionally, LLM's performance worsened as the number of clauses in the questions increased. This decline was linked to the models' inability to manage complex tasks, indicating a reliance on pattern-matching rather than logical reasoning. For example, adding a single, irrelevant clause to the question caused performance drops of up to 65% across all models, even though the added clause was not part of the reasoning process.
The authors also introduced GSM-NoOp, a dataset designed to test LLMs by adding seemingly relevant but ultimately irrelevant statements to questions. Most models failed to ignore these statements and incorrectly treated them as necessary for solving the problem. This highlights the models' dependence on pattern-matching rather than a proper understanding of mathematical reasoning. The study revealed that LLMs, even with multiple examples, struggle to ignore irrelevant context and fail to recognize necessary versus unnecessary information, indicating fragile reasoning processes. The study emphasizes the need for more reliable evaluation methods to assess LLMs' reasoning abilities accurately.
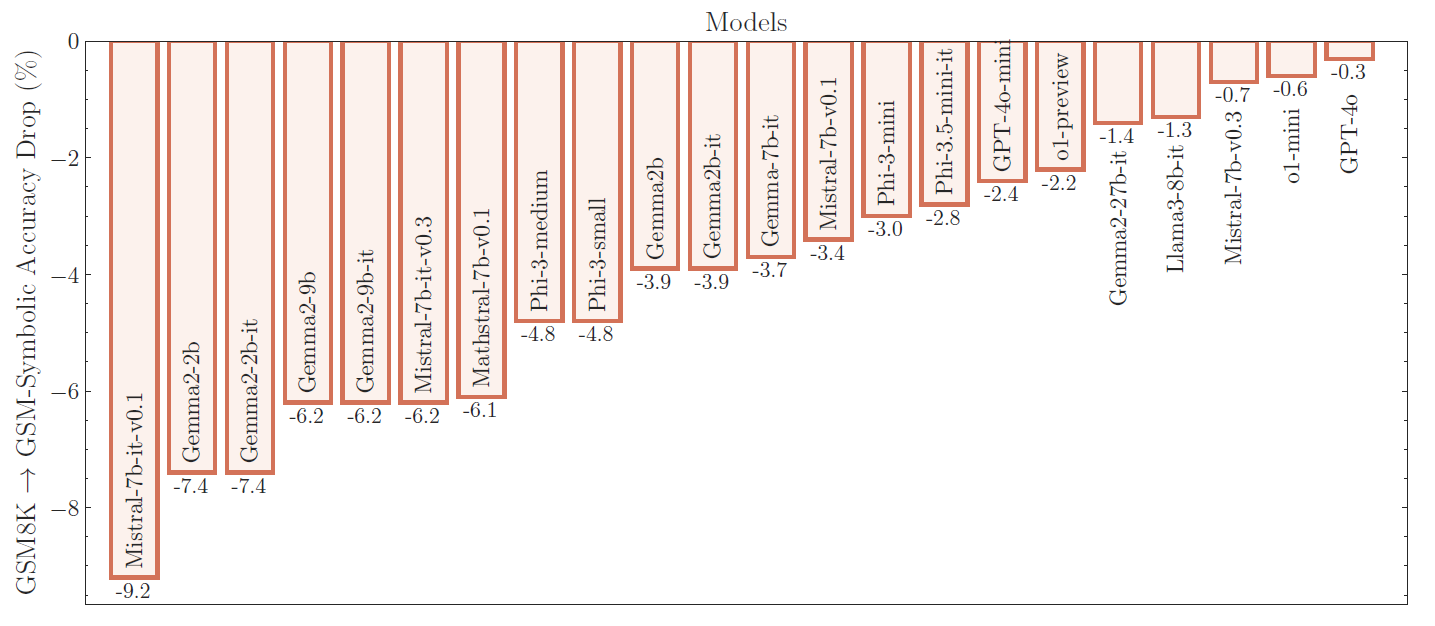 The performance of all state-of-the-art models on GSM-Symbolic drops compared to GSM8K. Later, we investigate the factors that impact the performance drops in more depth.
The performance of all state-of-the-art models on GSM-Symbolic drops compared to GSM8K. Later, we investigate the factors that impact the performance drops in more depth.
Applications
This research has significant implications for developing and evaluating LLMs. The developed benchmark offers a more reliable framework for assessing their reasoning abilities by generating diverse question variants and adjusting complexity levels. This helps scientists better understand the strengths and limitations of LLMs in handling mathematical tasks and guides the development of more capable models.
The findings also emphasize the need for improved evaluation methodologies beyond single-point accuracy metrics. By considering performance variability and the effects of different question variations, researchers can gain a deeper understanding of LLMs' reasoning capabilities and identify areas for improvement in model robustness and reasoning integrity.
 An example from the GSM-NoOp dataset: We add seemingly relevant statements to the questions that are, in fact, irrelevant to the reasoning and conclusion. However, the majority of models fail to ignore these statements and blindly convert them into operations, leading to mistakes.
An example from the GSM-NoOp dataset: We add seemingly relevant statements to the questions that are, in fact, irrelevant to the reasoning and conclusion. However, the majority of models fail to ignore these statements and blindly convert them into operations, leading to mistakes.
Conclusion and Future Directions
In summary, GSM-Symbolic proved an effective and reliable framework for comprehensively evaluating LLMs' mathematical reasoning. It revealed significant performance variability and fragility in existing state-of-the-art models, showing that they rely heavily on pattern-matching rather than genuine reasoning. The models showed high sensitivity to superficial changes, such as numerical or contextual modifications, leading to marked performance drops.
These findings highlight the need for improved evaluation methods and further research into LLM reasoning abilities. Future work should focus on developing AI models that can perform formal reasoning rather than solely relying on pattern recognition to achieve more robust and general problem-solving skills.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Mirzadeh, I., Alizadeh, K., Shahrokhi, H., Tuzel, O., Bengio, S., & Farajtabar, M. (2024). GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. ArXiv. https://arxiv.org/abs/2410.05229