They designed and trained a model capable of autonomously extracting 18 essential pieces of information from initial trial murder verdicts in South Korea, leveraging a comprehensive dataset constructed with the assistance of the generative pre-trained transformer (GPT-3.5). Their model demonstrated impressive accuracy and surpassed baseline models trained on publicly accessible datasets.
The 2021 amendment to South Korea’s criminal procedure law has significantly enhanced the role of the police as investigative authorities, leading to an increased demand for advanced investigative expertise and efficiency. However, the current situation poses many challenges for investigators, such as heavy workloads, insufficient manpower, complex information processing, and time-consuming tasks such as drafting investigation reports.
Hence, there is a pressing necessity for the development of artificial intelligence (AI) support systems capable of enhancing investigators' capabilities and aiding them in a multitude of tasks. These tasks may include but are not limited to extracting pivotal information from legal documents, scouring for precedents in similar cases, and constructing comprehensive case timelines. By leveraging AI-driven solutions, investigators can streamline their workflows, optimize resource allocation, and ultimately improve the efficiency and effectiveness of criminal investigations.
About the Research
The present paper aims to automate the extraction of key information essential for drafting investigation reports from various investigative documents using pre-trained language models. It defined 21 key pieces of information comprising the 'key information frame for murder case', including the victim’s name, age, gender, crime address, date and time, the motive of the crime, criminal act, outcome, etc.
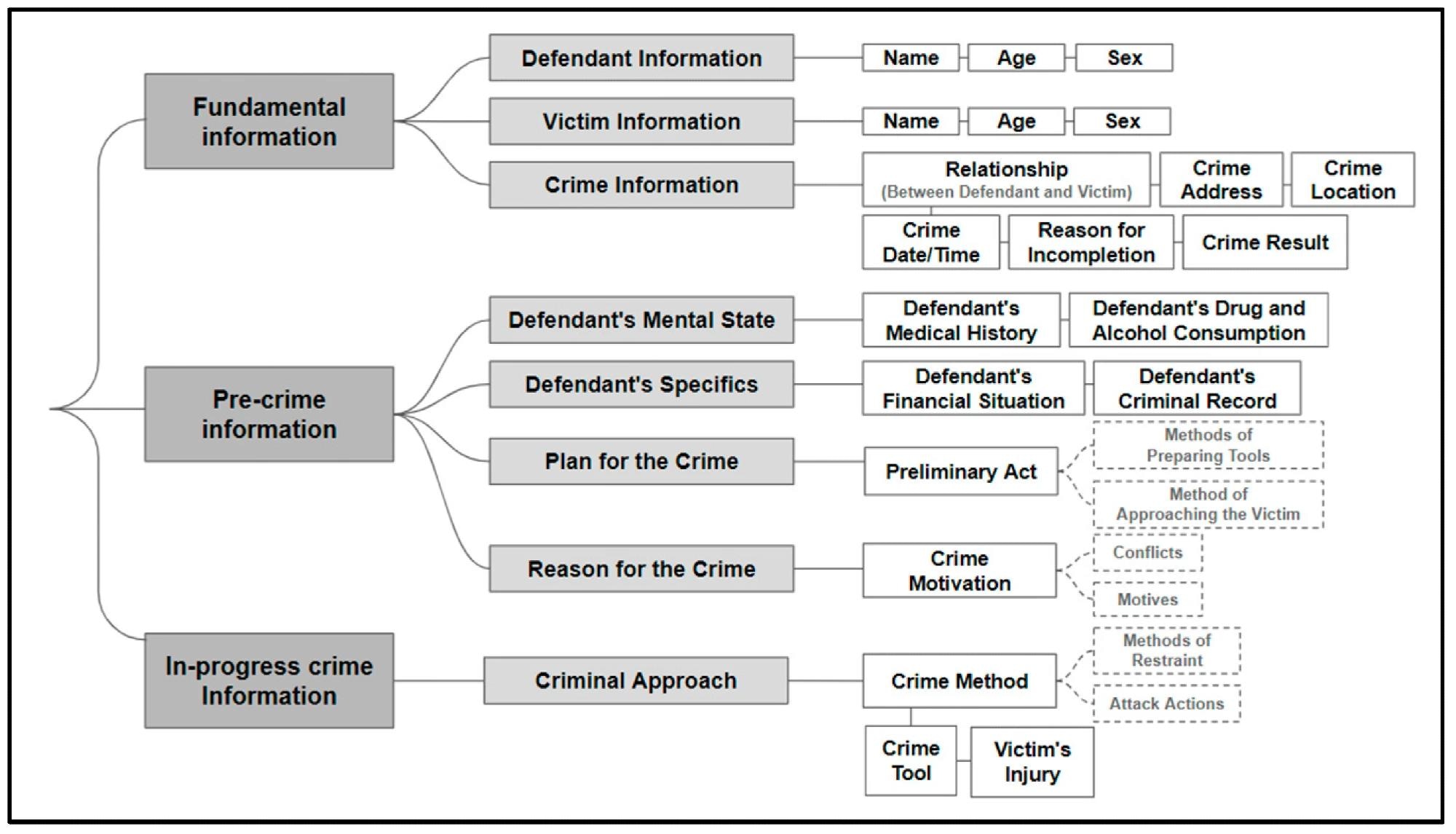 Key Information Frame for Murder Case.
Key Information Frame for Murder Case.
However, given that three pieces of information, namely, the suspect’s name, gender, and age, were redacted from the verdict documents utilized as the data source, the study concentrated on extracting the remaining 18 pieces of information.
The researchers constructed a large-scale dataset suitable for the crime investigation domain by leveraging a cutting-edge generative pre-trained language model, GPT-3.5, to annotate 1500 first-trial murder verdicts. They explored different prompt strategies, including simple, one-shot, and few-shot prompts, to identify the most effective approach for the key information extraction task.
Additionally, they assessed performance using metrics such as recall-oriented understudy for Gisting evaluation-longest common subsequence (ROUGE-L), recall, precision, and the harmonic mean of precision and recall (F1 score). The study revealed that the few-shots prompt yielded the highest performance and was selected for primary annotation. Furthermore, the authors conducted a secondary annotation and verification process involving human annotators to ensure the dataset's quality.
Additionally, a hybrid classification model was designed by combining a token classification model and a sequence classification model. The token classification model was utilized to extract eight token-type pieces of key information, including the victim’s name, age, gender, crime address, date and time, and crime tool. On the other hand, the sequence classification model was employed to extract 10 sequence-type pieces of key information, such as preparatory acts, criminal acts, motives for the crime, and outcomes.
Furthermore, the study employed five pre-trained language models: Korean language understanding evaluation bidirectional encoder representations from transformers (BERT) base (KLUE-BERT-base), Multilingual-BERT-base, cross-lingual language model Robustly optimized BERT approach (RoBERTa) base (XLM-RoBERTa-base), KLUE-RoBERTa-base, and Korean enhanced light efficiency cophasing telescope resolution actuator (ELECTRA) base (KoELECTRA-base). These models were fine-tuned on the key information extraction dataset. Additionally, two publicly available datasets, the Korean language understanding evaluation dataset for named entity recognition (KLUE-NER) and the Korean multi-label hate speech dataset (K-MHaS), were utilized as baselines for comparison.
Research Findings
The outcomes showed that the hybrid classification model, trained on the key information extraction dataset, outperformed the baseline models trained on publicly available datasets in both token and sequence classification tasks. Analysis of the model's predictions indicated that it correctly identified the answer within the top three ranks over 98% of the time for each key information category. However, the authors noted three types of misclassification errors and proposed potential solutions, including refining and augmenting the data, enhancing sequence segmentation rules, and incorporating diverse types of information.
The proposed model offers a valuable tool for extracting information essential for composing investigation reports, streamlining the process, and aiding decision-making for investigators while saving time on report writing. Its implementation can enhance investigation quality by ensuring accurate and consistent information inclusion, potentially leading to the standardization and automation of investigative processes.
Moreover, there is potential for further development to support additional investigation tasks, such as key-information-based similar case search systems or event timeline construction systems. These advancements could improve the fairness and efficiency of investigations by providing a standardized approach that goes beyond individual investigators' capabilities.
Conclusion
In summary, the novel model proved to be effective and efficient for extracting key information from complex legal and investigative documents. Moving forward, the researchers acknowledged limitations and challenges and suggested directions for further improving the performance and applicability of their technique. They recommended refining and augmenting the dataset, enhancing the sequence segmentation rules, and integrating the model with existing law enforcement and management systems.
 AI Image Generators Look Impressive But Still Fail Simple Instructions, Study Finds
AI Image Generators Look Impressive But Still Fail Simple Instructions, Study Finds