They proposed a Gaussian mixture models (GMMs) method to adapt speech assessment technology from German and Spanish to Czech, considering articulation, phonation, and prosody dimensions. Results showed promising accuracy in binary and tri-class classification scenarios, suggesting automated speech analysis combined with machine learning (ML) as a robust language differentiation tool.
Past work has highlighted the challenge of differentiating between PD and ET due to overlapping symptoms, necessitating exploring novel diagnostic approaches. Although researchers have explored various methods, including video examinations and signal analysis, they have yet to explore speech-based differentiation between PD and ET. The lack of standardized databases and the variability across languages pose significant challenges for developing a unified speech assessment framework.
Additionally, the complexity of speech patterns in neurological disorders and the need for large, diverse datasets further complicate the development of robust classification models. Moreover, ensuring the reliability and consistency of speech recordings across different clinical settings and populations presents another obstacle in the path toward effective speech-based differentiation of PD and ET.
Speech Analysis Methodology Overview
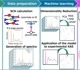
The methodology proposed in this study consists of six primary stages. Firstly, researchers considered databases containing speech recordings, which included participants diagnosed with ET, PD, and healthy controls. Subsequently, they extracted articulation, phonation, and prosody features from each speaker group.
Following this, researchers trained a universal background model (UBM) to capture the dynamics of the extracted features. Each speaker from the Czech corpora underwent adaptation using the maximum a posteriori (MAP) method to derive specific GMMs. Researchers generated supervectors using the mean vectors and covariance matrices of the adapted GMMs. Finally, a Support Vector Machine (SVM) classifier was employed to train and evaluate the Czech subjects, considering binary and tri-class classification scenarios.
The data utilized in this study included speech recordings from Czech-speaking participants, individuals diagnosed with ET and PD, and healthy controls. Additionally, databases from Spanish and German speakers were employed to train the methodology. The participants underwent specific tasks, including the rapid repetition of syllables (/pa-ta-ka/) and spontaneous monologue speech. Recordings were conducted in a controlled environment using a head-mounted condenser microphone, and neurological experts evaluated subjects according to established diagnostic criteria.
Feature extraction focused on articulation, phonation, and prosody, capturing distinct speech characteristics associated with motor speech disorders such as PD and ET. Researchers utilized GMMs to model the dynamics of the extracted features, with subsequent adaptation using the MAP method to tailor models to individual speakers. Researchers then generated supervectors to comprehensively represent each recording, incorporating statistical information from the adapted GMMs.
The classification was performed using a support vector machine (SVM) classifier with a Gaussian kernel, optimized through grid search for hyperparameter tuning. Training and evaluation were conducted using a stratified k-fold cross-validation strategy, repeated 10 times for improved generalization. Researchers evaluated accuracy, sensitivity, and specificity to assess the methodology's performance in differentiating between PD, ET, and healthy controls, facilitating further analysis of false positives and negatives.
Classification of Parkinson's Disease
This study conducted two experiments using data from the Czech corpus to classify patients with PD and ET. The first experiment focused on distinguishing between PD and ET patients, while the second aimed to classify PD patients, ET patients, and healthy control (HC) subjects. Researchers based the adaptation of Czech speakers on UBMs created using recordings from Spanish and German datasets and a combination of both.
They generated supervectors for each speech dimension and considered fusing them, followed by performing dimensionality reduction using principal component analysis (PCA). However, researchers found that including patients in the UBMs resulted in lower performance, possibly due to highly variable models and inadequate coverage of abnormal patterns arising from dysarthric symptoms. When supervisors adapted from the German UBM trained with controls were utilized, the bi-class classification task of PD patients vs. ET patients achieved its highest accuracy using a fusion of the three speech dimensions.
Similarly, for the tri-class classification task involving PD patients, ET patients, and HC subjects, the fusion of speech dimensions allowed for differentiation between the groups, with prosody exhibiting superior discrimination. The controlled /pa-ta-ka/ task consistently outperformed spontaneous speech tasks. Confusion matrices revealed distinct classification accuracies for each group, with prosody showing the most discriminative power between PD patients, ET patients, and healthy controls.
Visualization of the groups' distribution using linear discriminant analysis (LDA) further supported the classification results, showing a clear separation between ET patients and other groups, especially in the /pa-ta-ka/ task. Additionally, correlation analysis indicated that age and motor severity did not significantly affect the classification outcomes, suggesting robustness in the classification methodology independent of these factors.
Conclusion
To summarize, this study explored the classification of PD and ET patients using speech-based features. By adapting Czech speakers' data with UBMs trained from Spanish and German datasets, researchers generated supervectors for speech dimensions and applied dimensionality reduction. Results showed that the fusion of speech dimensions, particularly with supervisors adapted from the German UBM, accurately distinguished PD from ET patients. Prosody emerged as a discriminative factor, especially in the controlled task scenarios. These findings suggest the potential of speech-based approaches for accurate classification of motor disorders, independent of patient demographics.
 Tokyo Scientists Use AI to Decode Material Structures From X-Ray Spectra
Tokyo Scientists Use AI to Decode Material Structures From X-Ray Spectra