Study reveals how scaling visual tokenization with ViTok enhances image and video generation, setting new performance benchmarks while maintaining efficiency.
 Research: Learnings from Scaling Visual Tokenizers for Reconstruction and Generation. Image Credit: metamorworks / Shutterstock
Research: Learnings from Scaling Visual Tokenizers for Reconstruction and Generation. Image Credit: metamorworks / Shutterstock
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Visual tokenization via auto-encoding empowers state-of-the-art image and video generative models by compressing pixels into a latent space. Although scaling Transformer-based generators has been central to recent advances, the tokenizer component itself is rarely scaled, leaving open questions about how auto-encoder design choices influence both its objective of reconstruction and downstream generative performance.
This research aims to explore scaling in auto-encoders to fill this gap. To facilitate this exploration, the typical convolutional backbone is replaced with an enhanced Vision Transformer architecture for Tokenization (ViTok), which integrates Vision Transformers (ViTs) with an upgraded Llama architecture, forming an asymmetric auto-encoder framework.
ViTok is trained on large-scale image and video datasets, including Shutterstock and ImageNet-1K, which far exceed ImageNet-1K, removing data constraints on tokenizer scaling. The study first examines how scaling the auto-encoder bottleneck affects both reconstruction and generation—finding that while it is highly correlated with reconstruction, its relationship with generation is more complex, as larger bottlenecks can degrade generative performance due to increased complexity in channel sizes and convergence challenges.
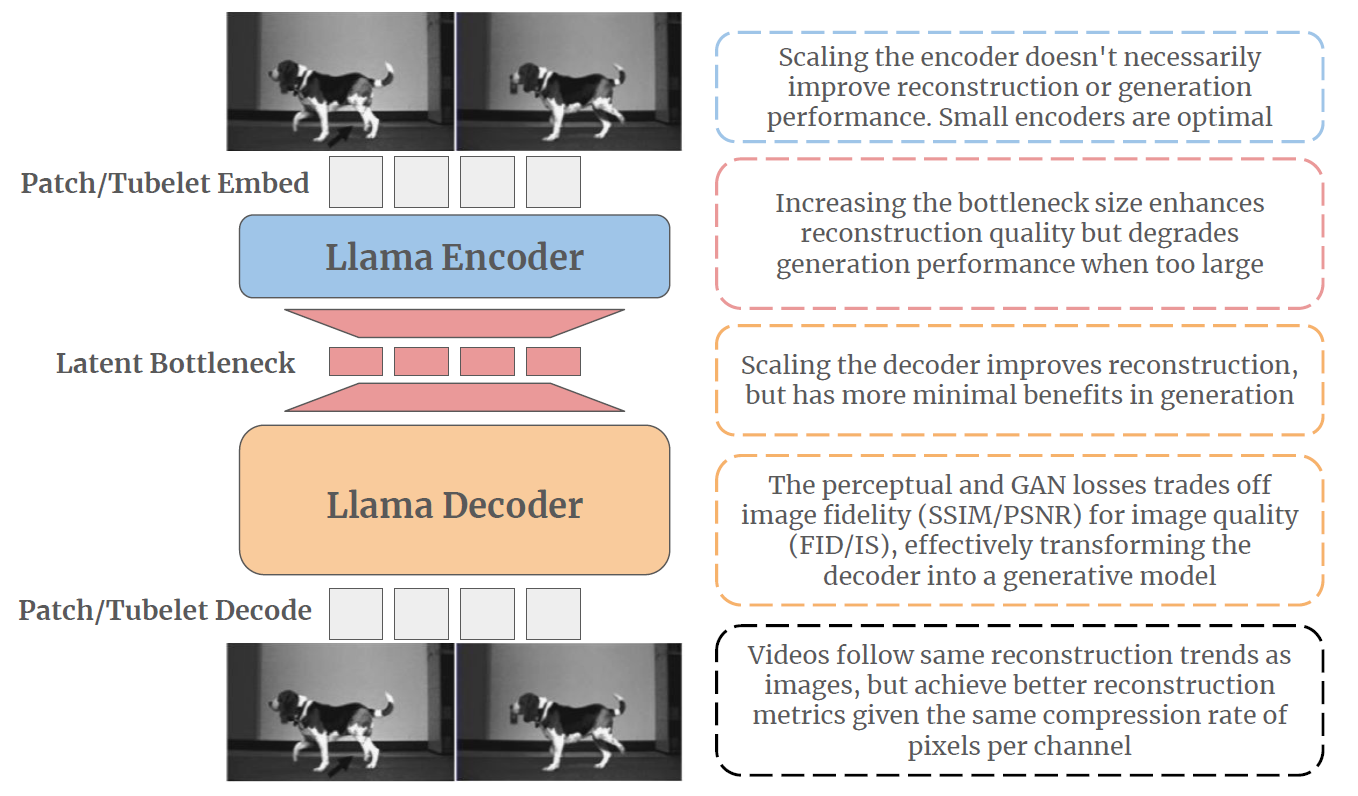
"Our learnings from scaling ViTok. We showcase our ViTok architecture (left) and key findings (right) from scaling auto-encoders for image and video reconstruction and generation. We enhance traditional CNN-based auto-encoders by integrating Vision Transformers (ViTs) with an upgraded Llama architecture into an asymmetric auto-encoder framework forming Vision Transformer Tokenizer or ViTok. Visual inputs are embedded as patches or tubelets, processed by a compact Llama Encoder, and bottlenecked to create a latent code. The encoded representation is then upsampled and handled by a larger Llama Decoder to reconstruct the input. Color-coded text boxes highlight the effects of scaling the encoder, adjusting the bottleneck size, and expanding the decoder. Additionally, we discuss trade-offs in loss optimization and the model’s adaptability to video data. Our best performing ViTok variant achieves competitive performance with prior state-of-the-art tokenizers while reducing computational burden."
Further exploration investigates the effect of separately scaling the auto-encoder encoder and decoder on reconstruction and generation performance. The findings indicate that scaling the encoder yields minimal gains for either reconstruction or generation and may even be detrimental while scaling the decoder boosts reconstruction, but the benefits for generation are mixed.
Building on this exploration, ViTok is designed as a lightweight auto-encoder that achieves competitive performance with state-of-the-art auto-encoders on ImageNet-1K and COCO reconstruction tasks (256p and 512p) while outperforming existing auto-encoders on 16-frame 128p video reconstruction for UCF-101, all with 2-5x fewer FLOPs compared to prior methods. When integrated with Diffusion Transformers, ViTok demonstrates competitive performance on image generation for ImageNet-1K and sets new state-of-the-art benchmarks for class-conditional video generation on UCF-101.
The study suggests that while scaling the auto-encoder bottleneck correlates strongly with reconstruction quality, its impact on generative performance requires a delicate balance, with larger bottlenecks potentially complicating model convergence and performance. Additionally, it is shown that videos, due to inherent temporal redundancy, allow for more efficient compression compared to images, requiring relatively lower compression rates to achieve similar reconstruction performance. Moreover, it is shown that increasing the encoder size yields minimal benefits and, in some cases, can hinder overall performance, whereas decoder scaling improves reconstruction but offers limited generative improvements. The decoder's role is further explored, with findings suggesting that it can act as an extension of the generative model, optimizing visual fidelity through trade-offs in loss functions.
By adopting an advanced Vision Transformer-based architecture and training on large-scale datasets, ViTok achieves impressive performance across image and video tasks while maintaining computational efficiency. These insights contribute to the broader understanding of how scaling strategies impact auto-encoder performance and provide valuable guidance for future advancements in generative modeling.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Yan, D., Chung, C., Zohar, O., Wang, J., Hou, T., Xu, T., Vishwanath, S., Vajda, P., & Chen, X. (2025). Learnings from Scaling Visual Tokenizers for Reconstruction and Generation. ArXiv. https://arxiv.org/abs/2501.09755