Dive into groundbreaking research that unveils the hidden gaps in AI reasoning and offers new tools to ensure consistent and reliable performance in real-world applications.
 Research: Are Your LLMs Capable of Stable Reasoning? Image Credit: Krot_Studio / Shutterstock
Research: Are Your LLMs Capable of Stable Reasoning? Image Credit: Krot_Studio / Shutterstock
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
In a recent article posted on the arXiv preprint* server, researchers at Shanghai AI Laboratory explored the capabilities of artificial intelligence (AI) techniques, particularly large language models (LLMs), in complex reasoning tasks, focusing on mathematical problem-solving. They aimed to highlight a significant gap between LLMs' performance on benchmark tests and their effectiveness in real-world applications, emphasizing the need for more robust evaluation metrics to assess model stability and reliability.
Advancement in Large Language Models
LLMs, such as the generative pre-trained transformer version 4 (GPT-4) developed by OpenAI and the LLaMA series presented by Meta AI, have transformed natural language processing tasks. These models have demonstrated exceptional capabilities in generating human-like text and solving complex problems. LLMs leverage large datasets and advanced machine-learning techniques to understand context, generate coherent responses, and perform reasoning tasks. However, as LLMs are deployed in real-world applications, evaluating their performance consistency and stability becomes increasingly important.
Existing evaluation protocols mainly focus on metrics like Greedy Accuracy and Pass@K, which measure peak performance but fail to capture model behavior across multiple attempts. These traditional metrics often overlook the nuances of output stability and consistency, particularly critical in complex reasoning tasks. This gap is especially critical in complex reasoning tasks like mathematical problem-solving, where accuracy and consistency are crucial for reliable results.
Novel Metrics to Overcome the Limitations of Existing Techniques
In this paper, the authors developed a comprehensive evaluation framework that accurately reflects the reasoning capabilities of LLMs. They introduced two innovative metrics, including G-Pass@k and LiveMathBench. The G-Pass@k metric enhances evaluation by considering both the potential and stability of model performance across multiple sampling attempts, providing a nuanced understanding of model behavior. It measures not only the peak performance potential of LLMs but also their stability across various sampling attempts, thus integrating stability and potential to offer a comprehensive overview of an LLM's capabilities, particularly in complex reasoning tasks.
To validate the effectiveness of the G-Pass@k metric, the researchers conducted extensive experiments using LiveMathBench, which includes challenging mathematical problems specifically designed to minimize data leakage risks during evaluation. LiveMathBench also includes multilingual and multi-difficulty question sets, ensuring comprehensive evaluation of LLMs across various scenarios. The benchmark continuously integrates current mathematical problems, ensuring its relevance to both the latest model capabilities and developments in mathematics. These experiments compared traditional metrics, such as Greedy Accuracy and Pass@K, with the newly introduced G-Pass@k, highlighting the limitations of conventional evaluation approaches.
Findings of Using Newly Developed Evaluation Metrics
The outcomes indicated significant insights into LLMs' performance when evaluated using the G-Pass@k metric. Notably, the analysis revealed considerable instability in reasoning across various models, with performance drops exceeding 50% in many cases, particularly under strict evaluation criteria. For example, the accuracy of several models sharply declined under the G-Pass@k evaluation compared to Greedy Accuracy, reflecting a significant gap between theoretical performance potential and real-world stability. This instability underscores the inadequacy of traditional metrics in capturing LLMs' true reasoning capabilities.
Additionally, the researchers highlighted that increasing model size does not necessarily lead to improved reasoning stability. There was a gap between the models' capabilities, as measured by G-Pass@k, and their actual stability during evaluation. This suggests that model size alone is insufficient to address reasoning consistency, emphasizing the need for alternative strategies in model design and evaluation.
The introduction of LiveMathBench provided valuable insights into the performance of various LLMs, including specialized models designed for mathematical reasoning. Through systematic comparisons between traditional metrics and G-Pass@k, the study showed different behavioral patterns among various model architectures. It also revealed how certain sampling parameters influence model performance, with G-Pass@k demonstrating robustness across a range of configurations. These results further highlighted the limitations of existing evaluation approaches.
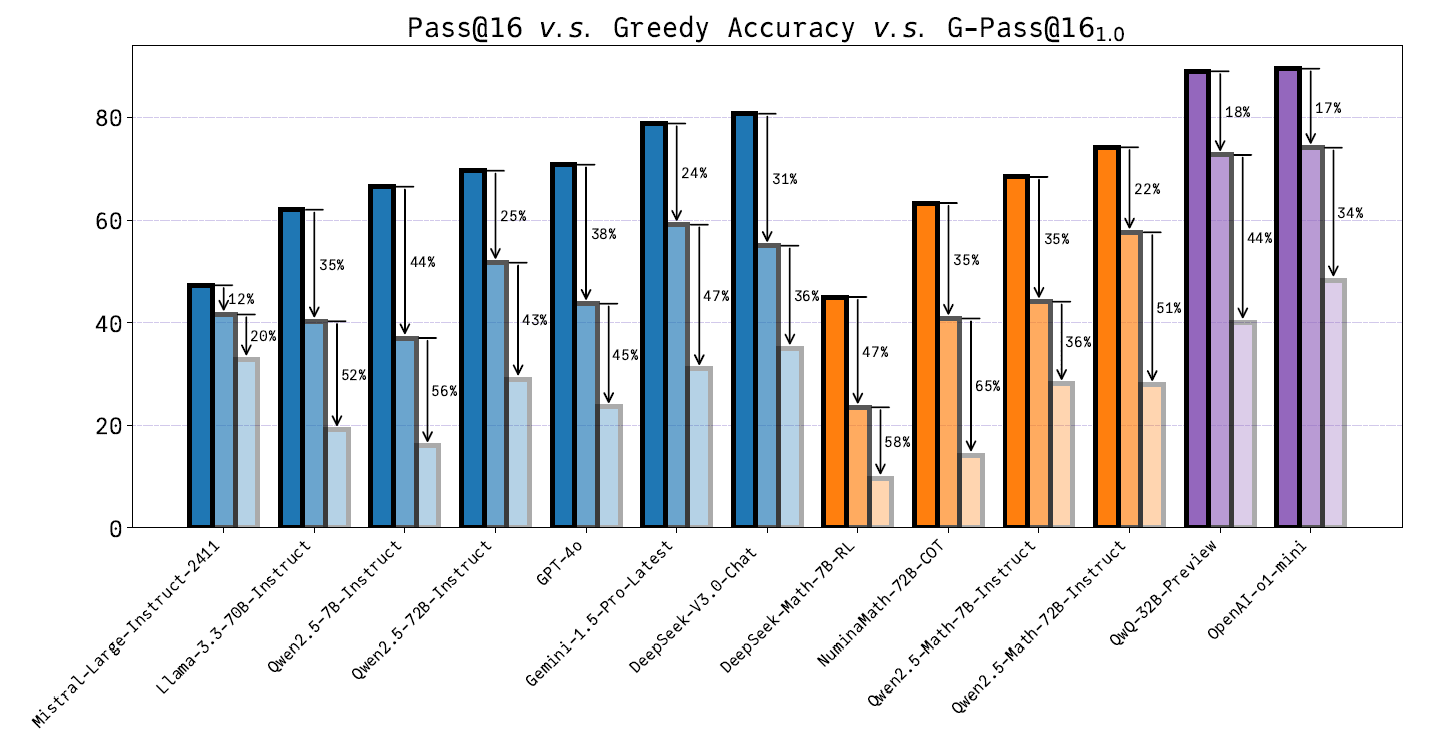
Pass@16 v.s. Greedy Accuracy v.s. [email protected] on LiveMathBench. This figure illustrates the gap between the performance of models using the Pass@16 criterion (dark bars), typical greedy output (semi-light bars), and the performance under the [email protected] criterion (light bars), highlights the instability of model performance across multiple samplings.
Practical Applications
This research has implications beyond academia, offering insights for practitioners and developers working with LLMs. By establishing a reliable framework for evaluating LLMs, it paves the way for improved model development and deployment in real-world applications.
The introduction of G-Pass@k and LiveMathBench provides essential tools for assessing model performance in areas requiring reliable and consistent outcomes (education, finance, and scientific research). The multilingual and dynamic nature of LiveMathBench ensures its relevance across diverse problem sets and applications. These metrics can be pivotal for developers aiming to create more robust and dependable language models. By focusing on stability and consistency in model performance, practitioners can ensure that LLMs are better suited for complex reasoning tasks, enhancing their effectiveness across various domains.
Conclusion and Future Directions
In summary, this study represents a significant advancement in evaluating LLMs, addressing the limitations of traditional assessment methods. By introducing G-Pass@k, which integrates stability and correctness, and LiveMathBench, which ensures a dynamic and multilingual evaluation framework, the authors provide a comprehensive foundation for understanding and improving the reasoning abilities of LLMs. As the demand for reliable AI systems increases, the authors highlight the importance of developing robust evaluation methods that accurately reflect the capabilities of these models, paving the way for their deployment in real-world applications.
As LLMs evolve, the need for rigorous evaluation methods will grow. Future work should focus on refining these metrics, exploring additional dimensions of model performance, and incorporating diverse problem sets to ensure comprehensive assessments. Continued exploration into the robustness of G-Pass@k across various hyperparameters and tasks could further enhance its utility. Overall, the development and application of G-Pass@k and LiveMathBench could lead to deeper insights into LLM capabilities, ultimately advancing the field of AI.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Liu, J., & et al. Are Your LLMs Capable of Stable Reasoning?. arXiv, 2024, 2412.13147. DOI: 10.48550/arXiv.2412.13147, https://arxiv.org/abs/2412.13147
 Why Human AI Teams Fail and How Cognitive Alignment Unlocks Better Collaboration
Why Human AI Teams Fail and How Cognitive Alignment Unlocks Better Collaboration