Researchers reveal how state-of-the-art AI models excel at surface-level tasks but falter under deeper scrutiny, highlighting the need for smarter generative systems.
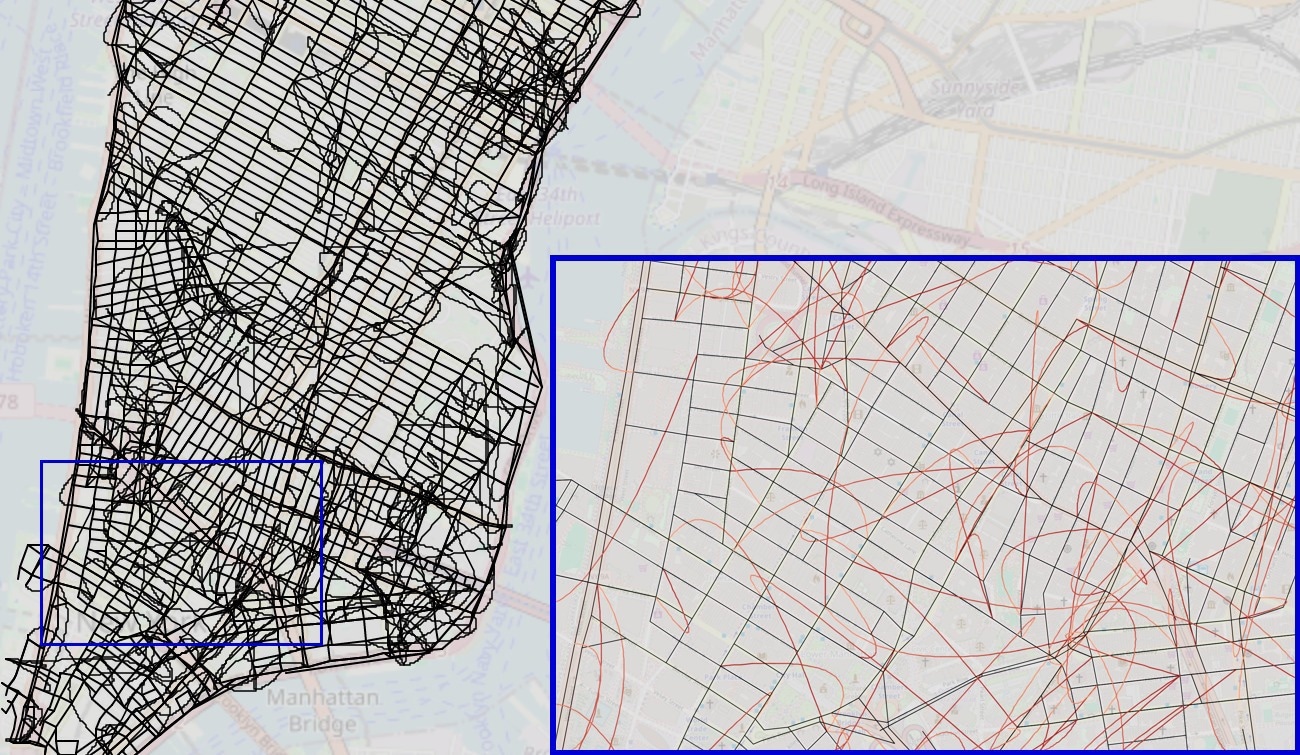
Reconstructed map from transformer trained on shortest paths. In the zoomed-in images, edges belonging to the true graph are black and false edges added by the reconstruction algorithm are red with a darkening gradient indicating the directionality of the edge. Interactive map available at https://manhattan-reconstruction-shortest.netlify.app/.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
In an article recently submitted to the arXiv preprint* server, researchers in the United States explored whether large language models (LLMs) implicitly learned "world models" that captured the logic of underlying domains like navigation, game-playing, and logic puzzles. Using evaluation metrics inspired by the Myhill-Nerode theorem, the authors assessed these models' coherence in representing such systems. They illustrated these findings with examples, such as modeling navigation in New York City and understanding board games like Othello. The findings revealed significant incoherence, leading to task failures, and highlighted the need for improved generative models that more accurately captured domain logic.
Background
LLMs have demonstrated remarkable capabilities, often surpassing their original design for next-token prediction by implicitly capturing high-fidelity representations of their training domains. This ability has led to applications in diverse areas such as navigation, game-playing, and scientific domains like protein generation and chemistry. For example, in navigation, LLMs trained on turn-by-turn directions have shown the potential to replicate city maps without explicit mapping. However, deeper analyses reveal that such learned representations often fail to align with true map structures. Previous work, including studies on games like chess and Othello, explored whether LLMs can recover underlying domain rules. These approaches often relied on intuitive metrics, such as next-token prediction validity. However, these methods fell short in diagnosing deeper issues, such as the coherence and accuracy of the inferred world models, especially for tasks requiring subtle distinctions in domain logic.
This paper addressed these gaps by introducing evaluation metrics inspired by the Myhill-Nerode theorem, specifically designed to assess state transitions and sequence distinctions in deterministic finite automata (DFA). The authors revealed significant inconsistencies in world models inferred by LLMs by applying these metrics to domains like navigation, game-playing, and logic puzzles. For instance, in the context of Connect-4, the study illustrated how even a simplistic generative model that outputs uniform next-token predictions can perform well on surface-level metrics while failing to recover deeper structural logic. This work provided a robust framework for evaluating and refining LLMs to build more accurate and reliable world models.
Framework
The framework integrated generative sequence models with DFA by leveraging their common foundation of tokens, sequences, and languages. Generative models predicted the probability distribution of the next token based on a sequence, while DFAs accepted or rejected sequences based on defined transition states. A generative model was said to recover the DFA if it generated only valid sequences as per the DFA's language, verified through exact next-token prediction.
The paper critiqued next-token prediction as a fragile metric for evaluating world model recovery. For example, in Connect-4, a model generating random moves might score high on next-token prediction despite not encoding any meaningful game-state information. This limitation was addressed through the Myhill-Nerode theorem, which delineated boundaries between DFA states. The interior included shared sequences across states, while the boundary contained minimal sequences distinguishing states.
Two new metrics—compression and distinction—were proposed to evaluate generative models effectively. The sequence compression metric tested whether a model identified sequences leading to the same state, focusing on precision. The sequence distinction metric measured the ability to differentiate states using boundary recall and precision. These metrics revealed substantial gaps in models' ability to generalize and distinguish between states, even when next-token prediction appeared successful.
Insights from Maps and Games
The researchers explored the ability of transformers to model real-world systems using New York City taxi rides. Researchers trained transformers to predict sequences of turn-by-turn directions, showing that these models could often find valid and shortest routes between intersections. However, graph reconstruction techniques revealed that the implicit maps created by these models bore little resemblance to the actual Manhattan street map. Reconstructed maps often included physically impossible features, such as misaligned street orientations or overlapping streets, highlighting the models' incoherent world models. Models trained on random walks were more robust to detours than those trained on shortest or noisy shortest paths, illustrating the limitations of the latter approaches. Despite excelling at tasks like next-token prediction and probing current states, transformers struggled with advanced metrics such as sequence compression and distinction, which measured their ability to generalize and distinguish between states.
Beyond navigation, similar evaluations were applied to other domains, such as Othello and logic puzzles. Models trained on synthetic Othello data outperformed those trained on real-world tournament games, as they demonstrated better structural recovery and robustness. In logic puzzles, even highly capable models, like GPT-4, often failed to exhibit coherent world models, as revealed by compression and distinction metrics.
Conclusion
In conclusion, the researchers evaluated whether LLMs effectively captured "world models" in domains like navigation and logic puzzles. Using metrics inspired by the Myhill-Nerode theorem, the study revealed significant inconsistencies in these models' inferred structures. While LLMs demonstrated impressive next-token prediction and task performance, they struggled with coherence and generalization, especially under disruptions. The proposed metrics, focusing on sequence compression and distinction, offered deeper insights into model limitations. Graph reconstruction in navigation tasks and detour-handling experiments further underscored the practical fragility of incoherent world models. Although the study primarily addressed DFA, the findings suggested broader applicability, highlighting the need for more robust generative models to enhance accuracy and reliability in diverse domains.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference:
- Preliminary scientific report.
Vafa, K., Chen, J. Y., Rambachan, A., Kleinberg, J., & Mullainathan, S. (2024). Evaluating the World Model Implicit in a Generative Model. ArXiv.org. DOI:10.48550/arXiv.2406.03689, https://arxiv.org/abs/2406.03689