A scaling study with up to 8 billion parameters and 4 trillion training bytes demonstrated improved training and inference efficiency, especially for predictable data, along with better reasoning and generalization. The model exhibited superior scalability compared to tokenization-based models at fixed inference costs. BLT's ability to simultaneously scale patch and model size while maintaining a fixed inference budget underscores its potential for efficiency in large-scale language modeling.
Related Work
Past work on character-level models highlighted their flexibility for handling out-of-vocabulary words and morphologically rich languages. While BLT, like character-aware neural information encoder (CANINE) and ByT5, improved robustness, they faced challenges with compute efficiency due to longer sequences. Recent innovations, such as entropy-based patching and cross-attention mechanisms in BLT, overcome these challenges by dynamically segmenting data into patches based on information density.
Efficient Byte Processing
The BLT architecture consists of a large global autoregressive language model and two smaller local models: a local encoder and a local decoder. The global model processes latent patch representations using a Latent Global Transformer, an autoregressive transformer with block-causal attention, enabling efficient computation by limiting attention to current patches. This design ensures scalability, as the global model handles the bulk of computation during pretraining and inference, allowing flexibility in resource allocation based on input/output complexity. Dynamic patching methods allow BLT to process data with varying levels of complexity, saving computational resources on simpler inputs.
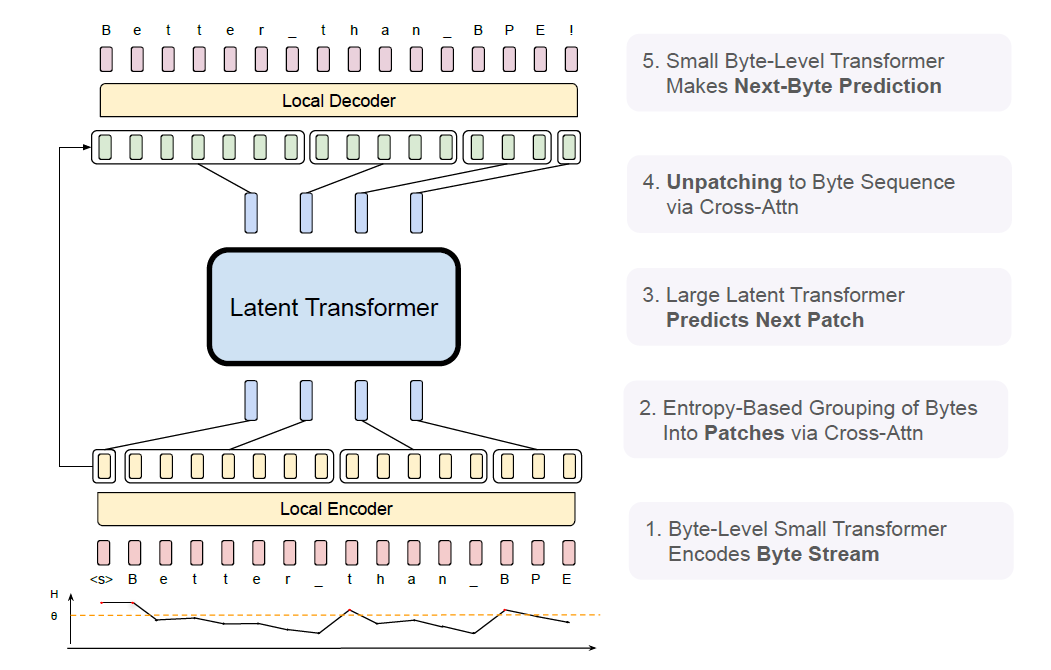
BLT comprises three modules, a lightweight Local Encoder that encodes input bytes into patch representations, a computationally expensive Latent Transformer over patch representations, and a lightweight Local Decoder to decode the next patch of bytes. BLT incorporates byte n-gram embeddings and a cross-attention mechanism to maximize information flow between the Latent Transformer and the byte-level modules. Unlike fixed-vocabulary tokenization, BLT dynamically groups bytes into patches preserving access to the byte-level information.
The local encoder, a lightweight transformer with cross-attention layers, maps input byte sequences into expressive patch representations. It incorporates hash-based n-gram embeddings to capture contextual information from preceding bytes, ensuring robust and expressive representations. This design improves the model's ability to handle noisy and low-resource data effectively.
The local decoder, similarly lightweight, reverses the process by decoding patch representations into raw bytes. It uses cross-attention layers where byte representations are queries, and patch representations act as keys and values. Both encoder and decoder employ multi-headed attention, pre-layer normalization, and residual connections for efficient transformation. Flex attention in these components further optimizes training and inference. These components collectively enable BLT to process byte-level inputs efficiently, balancing compute costs while maintaining robust modeling capabilities.
BLT Model Evaluation
Controlled experiments were conducted to compare BLT with tokenization-based models, ensuring fairness by maintaining similar sequence context lengths. Pretraining was performed on two datasets: the Llama 2 dataset, consisting of 2 trillion tokens, and BLT-1T, a new dataset of 1 trillion tokens that includes public data and a subset from datacomp-LM. The Llama 2 dataset was utilized for scaling law experiments to determine optimal architecture choices, while BLT-1T facilitated full pretraining for downstream task comparisons with Llama 3. Both datasets excluded data from Meta products or services. Entropy thresholds for patching were tuned to ensure optimal balance between context length and compute efficiency. BLT models employed entropy-based patching with context lengths of 8k bytes for Llama 2 data and 16k for BLT-1T, maintaining consistent batch sizes while adjusting sequence lengths to ensure computational efficiency.

An example of default entropy-based patching with global threshold during inference on mmlu. Green denotes the prompt, Blue denotes the few-shot examples, and red denotes the question to be answered. Note that the size of the patches for the repeated phrases in the answer choices is much larger, which means that the global model is invoked significantly fewer times than its tokenizer-based counterpart, with this inference patching scheme.
The BLT transformer architecture incorporated innovations such as switched gated linear units (SwiGLU) activation, rotary positional embeddings, root mean square normalization (RMSNorm) for layer normalization, and flash attention for efficient training. These features enabled BLT to achieve performance parity with tokenization-based models while reducing inference flops by up to 50%. Dynamic patching methods and entropy-based thresholds enabled the efficient handling of structured and repetitive content, while modifications like flex attention optimized cross-attention layers. Models were scaled from 400M to 8B parameters, using consistent hyperparameters across experiments. Training employed the AdamW optimizer with a warm-up, cosine decay schedule, global gradient clipping, and weight decay for stability. Bits-per-byte (BPB) served as a tokenizer-independent evaluation metric, demonstrating BLT's performance on par with state-of-the-art token-based models like Llama 3.
Scaling with BLT
The scaling trends of BLT models were examined, showing that BLT models, trained with optimal compute ratios, perform on par with or better than byte pair encoding (BPE) models, particularly as model size and compute scales. Unlike token-based models, BLT leverages larger patch sizes to reduce inference steps while maintaining high performance, resulting in significant compute savings. Using dynamic patching strategies and larger patch sizes, BLT models achieve significant inference cost savings while maintaining competitive performance on various benchmarks. Inference performance improves with larger patch sizes, especially in larger models. Additionally, BLT outperforms traditional token-based models in tasks requiring robustness to noise and awareness of language constituents. This advantage is particularly evident in low-resource machine translation and sequence manipulation tasks. These results indicate that byte-level models scale efficiently, especially when trained with larger patches and models.
BLT Model Robustness
BLT models demonstrate superior robustness to noise and better character-level awareness than token-based models, excelling in tasks like grapheme-to-phoneme conversion and sequence manipulation. BLT outperforms Llama 3 in low-resource machine translation, especially in translating into and out of lower-resource languages. Initializing BLT from pre-trained Llama 3 significantly improves performance, with BLT models surpassing Llama 3 and baseline BLT models on various benchmarks. This initialization strategy reduces training time and computational requirements while preserving accuracy.
Conclusion
To sum up, the BLT introduced a dynamic, learnable approach to grouping bytes into patches, enhancing efficiency and robustness in large language models. BLT matched the performance of tokenization-based models like Llama 3, achieving up to 50% reduction in inference flops. It allowed simultaneous model and patch size increases within a fixed inference budget, improving scalability. With its superior robustness to noise and awareness of sub-word structures, BLT offers a compelling alternative to tokenization-based models, paving the way for more efficient and adaptable language modeling.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Pagnoni, A., Pasunuru, R., Rodriguez, P., Nguyen, J., Muller, B., Li, M., Zhou, C., Yu, L., Weston, J., Zettlemoyer, L., Ghosh, G., Lewis, M., Holtzman, A., & Iyer, S. (2024). Byte Latent Transformer: Patches Scale Better Than Tokens. ArXiv. https://arxiv.org/abs/2412.09871