StyleMaster achieved superior video stylization by combining global and local style features, enabling high-quality, style-aligned video generation. The framework demonstrates significant advancements in the field by leveraging comprehensive datasets and innovative design choices. Extensive experiments showed its effectiveness over existing methods.
Background
Video generation has achieved significant advancements, mainly due to the rise of diffusion models, which offer both high-quality outputs and improved controllability. Among various aspects, style control—transforming or generating videos to match the artistic style of a reference image—has garnered interest but remains underexplored.
Existing methods, such as VideoComposer and StyleCrafter, struggle with key challenges: preserving local texture details, balancing global style representation, and avoiding content leakage. For example, StyleCrafter often captures only superficial style elements like color, while VideoComposer suffers from excessive content copying. Current approaches often either focus excessively on global styles, lose fine details like brushstrokes, or overuse reference features, leading to copying and distortion of content.
This paper introduced StyleMaster, a framework designed to address these gaps by combining global and local style extraction. Local texture information was filtered to prevent content leakage, while a novel dataset of paired images with absolute style consistency was generated using a "model illusion" technique for effective global representation learning.
Furthermore, a motion adapter ensured temporal coherence and stylization in videos, and a gray tile ControlNet offered precise content guidance. The gray tile approach specifically mitigates color interference in style transfer, enhancing content alignment without compromising stylistic accuracy.
Extensive experiments demonstrated that StyleMaster excelled in stylized video generation and video style transfer, outperforming existing style resemblance and temporal consistency methods. Metrics such as the Content Style Decoupling (CSD) score and ArtFID revealed StyleMaster's superiority in balancing style fidelity and content preservation.
Proposed Methodology
StyleMaster generated stylized content with improved style consistency, dynamic quality, and content control. It consisted of multiple components to achieve accurate style extraction and application.
It used a model illusion technique to automatically create a large, consistent style dataset. This dataset uniquely ensures high intra-group style consistency by rearranging image pixels while maintaining the desired stylistic features, offering a scalable and cost-effective solution.
Instead of fine-tuning the entire contrastive language-image pre-training (CLIP) encoder, StyleMaster employed a lightweight transformation using a multi-layer perceptron (MLP) layer. This approach isolated global style features while preserving CLIP’s generalization ability.
The result was a uniform style representation across an entire image. StyleMaster combined global and local style features for optimal representation. Local textures were extracted by selecting image patches with minimal similarity to the content prompt. This selection process avoids content leakage while enhancing stylistic textures like brushstrokes or intricate patterns.
A motion adapter modified temporal attention blocks to address temporal flickering and enhance style dynamics. It smoothly transitioned between static and dynamic effects, enabling better stylization across frames. Setting a negative scaling factor in the motion adapter further amplified stylization by moving outputs away from real-world domains. A grayscale image tile was used for effective content guidance to avoid interference from color information during style transfer, ensuring precise alignment between content and style.
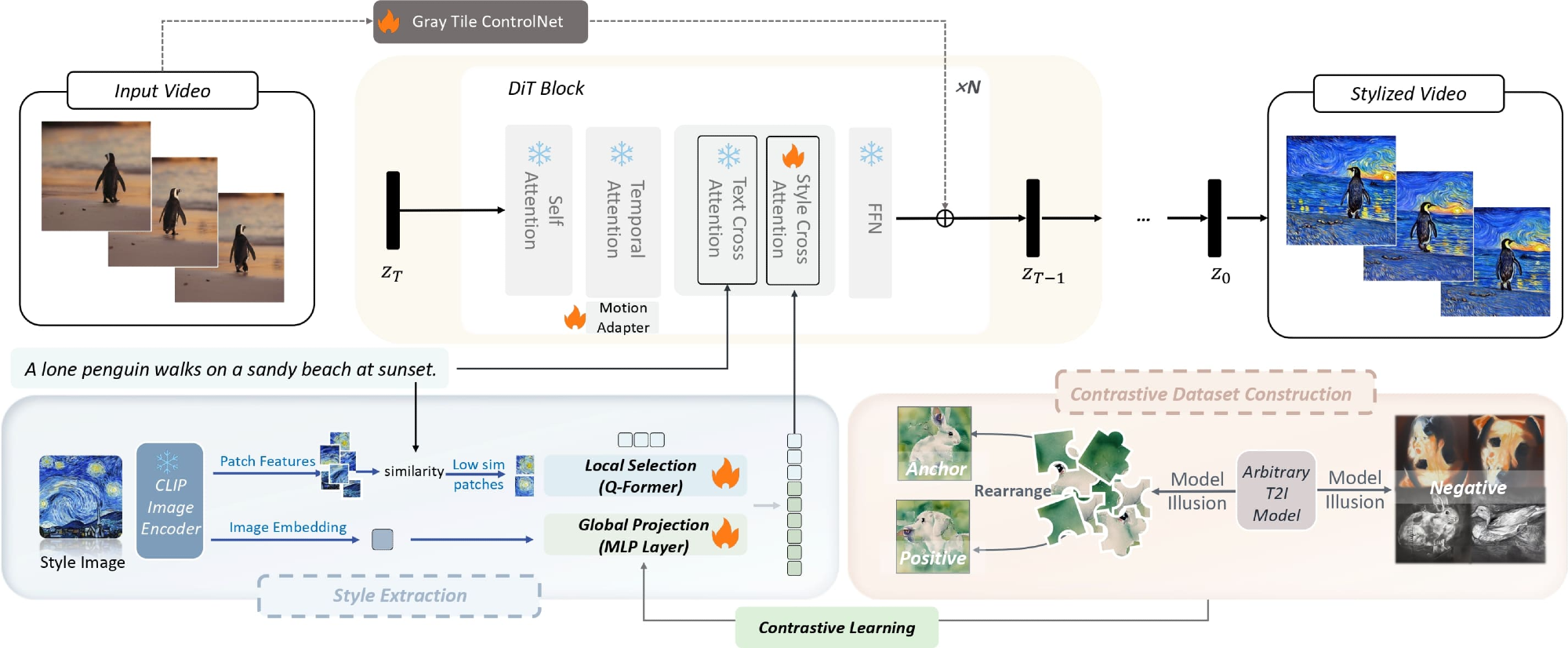
We first obtain patch features and image embedding of the style image from CLIP, then we select the patches sharing less similarity with text prompt as texture guidance, and use a global projection module to transform it into global style descriptions. The global projection module is trained with a contrastive dataset constructed by model illusion through contrastive learning. The style information is then injected into the model through the decoupled cross-attention. The motion adapter and gray tile ControlNet are used to enhance dynamic quality and enable content control respectively.
Experimental Setup and Results
The proposed method was based on a diffusion transformer (DiT)-based video generation model, incorporating a three-dimensional (3D) causal variational auto-encoder (VAE) and DiT Blocks for denoising.
The training involved several steps. The global style extractor was trained on 10K pairs of style data generated through model illusion using contrastive learning, followed by training the motion adapter with still videos and style modulation with the Laion-Aesthetics dataset
Finally, a gray tile ControlNet was trained for content control. The training was performed on eight A800 graphic processing units (GPU) and completed within two days. This efficient training pipeline highlights the model's scalability and feasibility for broader applications. Classifier-free guidance was applied with text and style configuration set to 12.5 and six, respectively.
The test dataset included 192 style-prompt pairs for video stylization and 96 content-style pairs for image style transfer. The method achieved superior style resemblance and content preservation in image style transfer compared to state-of-the-art techniques, particularly in metrics such as ArtFID and CSD score.
For video stylization, it surpassed competitors in text-video alignment, dynamic quality, and motion smoothness. Although CSD scores were marginally lower, this reflected an intentional balance between style fidelity and text alignment rather than excessive copying of reference features.
Key designs, like the global projection and selective token use, significantly improved text alignment and style fidelity. The motion adapter balanced style and dynamics, while gray tile guidance enhanced content control and layout precision.
Conclusion
In conclusion, the researchers introduced StyleMaster, a novel framework for video style transfer that combined global and local style representations to address challenges like content leakage, poor style fidelity, and temporal inconsistencies.
Using contrastive learning with a "model illusion" technique, the authors achieved consistent global style extraction while filtering local textures to preserve fine details. A motion adapter improved temporal coherence, balancing static and dynamic effects, while gray tile ControlNet ensured precise content control.
Extensive experiments demonstrated superior performance in style resemblance, text alignment, and dynamic quality, outperforming state-of-the-art methods and establishing StyleMaster as a robust solution for video stylization. The framework also opens doors for future innovations, including dynamic style elements beyond static reference images.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference:
- Preliminary scientific report.
Ye, Z., Huang, H., Wang, X., Wan, P., Zhang, D., & Luo, W. (2024). StyleMaster: Stylize Your Video with Artistic Generation and Translation. ArXiv. https://arxiv.org/abs/2412.07744