They identified scaling consistency, where design decisions on smaller models effectively transfer to larger ones and found frames-per-second (fps) sampling superior to uniform frame sampling during training.
Using these insights, they developed Apollo, a state-of-the-art LMM family capable of efficiently perceiving hour-long videos. Apollo-3B scored 68.7 on MLVU, surpassing larger models like Oryx-7B, while Apollo-7B set a new benchmark of 70.9, rivaling models with over 30B parameters. These results underscore Apollo’s ability to deliver top performances on benchmarks like LongVideoBench and long video understanding (MLVU).
Improving Video Benchmarks
Researchers analyzed the effectiveness of existing video question-answering benchmarks, highlighting issues such as redundancy and resource intensiveness.
They found that many benchmarks relied more on text comprehension or single-frame images than video perception. Redundancies were observed between benchmarks, with high correlations between short and long video groups and between different question formats.
Based on these insights, they introduced ApolloBench, a more efficient benchmark suite focused on video perception. It achieves faster evaluations —41× faster compared to traditional benchmarks— while maintaining a strong correlation with existing benchmarks.
ApolloBench was designed to filter out questions that did not require video input, ensuring a more discriminative evaluation. For example, only questions requiring video perception were retained, significantly improving its focus on temporal reasoning and perception tasks.
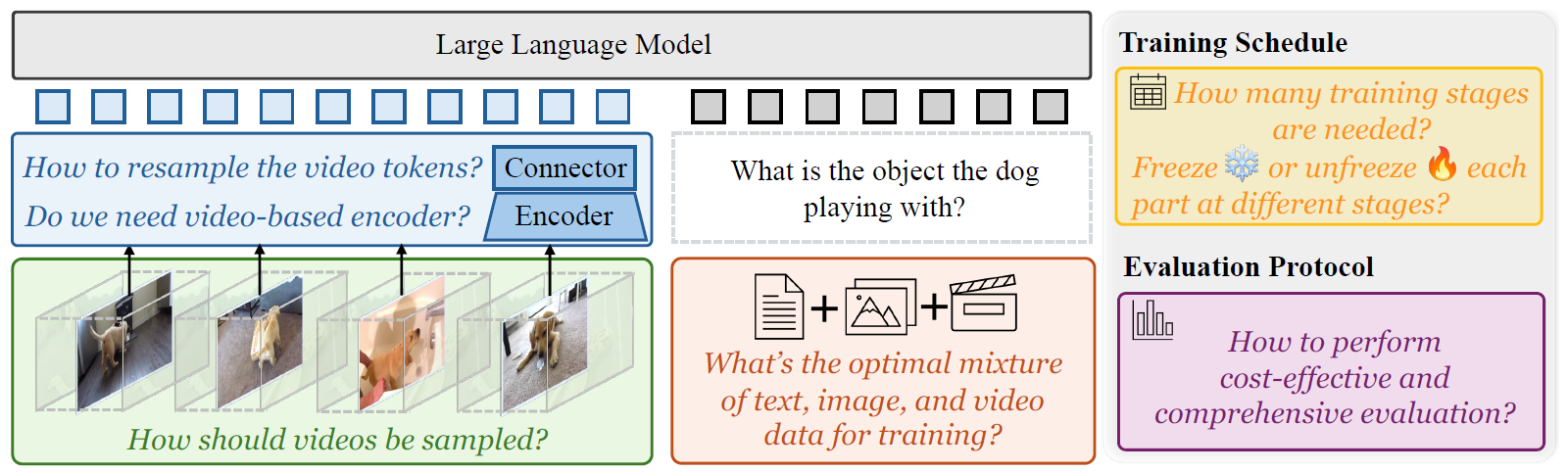
Apollo exploration. Schematic illustrating our comprehensive exploration of video-specific design choices; critically evaluating the existing conceptions in the field, from video sampling and model architecture to training schedules and data compositions. For example, we found that the SigLIP encoder is the best single encoder for video-LMMs but can be combined with additional encoders to improve temporal perception, and that keeping a ∼ 10% text data during fine-tuning is critical for video understanding performance.
Scaling Consistency Insight
Analysts explored scaling consistency in LMMs, discovering that design decisions made on moderately sized models (2–4B parameters) can reliably transfer to larger models (7B). This eliminates the need for extensive scaling studies, reducing computational costs.
The study found a strong correlation (R2 > 0.9) between models of different sizes, particularly between the 4B and 7B models. Interestingly, dataset sizes of around 500K samples were sufficient for these models, with diminishing returns beyond this threshold. This insight accelerates the development of LMMs by making design decisions more transferable.
Optimizing Video-Text Models
Key architectural design choices for LMMs in video-language tasks are explored, focusing on video sampling, representation, token resampling, and integration. It was found that fps sampling outperformed uniform sampling during both training and inference, addressing issues related to playback speed.
Combining video and image encoders proved crucial, with SigLIP-SO400M and InternVideo2 performing best. When integrated, these encoders achieved a 7% improvement in ApolloBench compared to single encoders. The perceiver resampler stands out as the top performer among token resampling methods. The study highlights the trade-offs between token rate and fps, suggesting an optimal range for achieving high performance.
Training Protocols Optimized
Different training schedules and protocols were explored for video-LMMs, focusing on the impact of single, two-stage, and three-stage training approaches. Gradual training, with progressively unfreezing model components, yielded the best performance. For instance, the three-stage schedule yielded an overall ApolloBench score of 59.2, outperforming two-stage configurations. The training process typically involves mixed text, image, multi-image, and video data, with several configurations tested.
The results revealed that a three-stage training schedule outperformed the others, especially when the model components were progressively unfrozen and trained on varying data compositions, such as video-heavy or balanced datasets. Including 10–14% of text data in the training mix was found essential to avoid catastrophic forgetting.
The study also examined the role of training video encoders and data composition in model performance. Video LMMs benefit from training the vision encoders exclusively on video data, improving performance in reasoning and domain-specific applications.
Additionally, the composition of the training data significantly impacted model effectiveness. Including about 10-14% of text data was crucial for avoiding catastrophic forgetting, while a slightly video-heavy mix of data types led to the best overall performance. A balanced data mixture was essential for maintaining optimal model performance across different tasks.
Apollo: Powerful Video-LMMs
The Apollo family of LMMs delivers state-of-the-art performance across various model sizes, frequently outperforming models two to three times their size. The backbone of Apollo models is based on the Qwen2.5 series of large language models (LLMs), with 1.5B, 3B, and 7B parameters. The architecture integrates the SigLIP-SO400M encoder with the InternVideo2 video encoder, with features interpolated and concatenated along the channel dimension and resampled to 32 tokens per frame.
Apollo models were trained using a three-stage training schedule on a diverse dataset mixture, including text, image-text, multi-image, and video modalities, with data generated through multi-turn video-based conversations powered by LLaMA 3.1. The results across various benchmarks such as TempCompass, MLVU, and video-multimodal embedding (MME) reveal Apollo’s strong performance. Apollo-7B, for example, scored 70.9 on MLVU, surpassing even models like VILA1.5-40B with over 30B parameters.
Despite their smaller parameter counts, Apollo-1.5B and Apollo-3B models perform impressively, making them suitable for rapid prototyping in practical applications. With its robust performance across multiple tasks, Apollo establishes itself as a powerful family of models, pushing the boundaries of video-language understanding and outperforming larger models in several key benchmarks.
Conclusion
To sum up, the study critically evaluated the current state of video LMMs, emphasizing key design aspects like scaling consistency, encoder selection, and token integration. It introduced Apollo, a family of models that outperformed larger counterparts like Apollo-3B and Apollo-7B.
The findings demonstrated that thoughtful design and training could achieve superior performance without relying on larger models. ApolloBench, with its focus on temporal reasoning, provides a faster yet effective evaluation framework, further advancing the field. This work offered valuable insights and resources for advancing efficient video-LMM development.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference:
- Preliminary scientific report.
Zohar, O., et al. (2024). Apollo: An Exploration of Video Understanding in Large Multimodal Models. ArXiv. DOI: 10.48550/arXiv.2412.10360, https://arxiv.org/abs/2412.10360