The team created a synthetic urban dataset, Genex database (Genex-DB), to train the model and demonstrated that it generated consistent, high-quality observations using a novel spherical-consistent learning (SCL) objective. This innovation ensures edge continuity in panoramic outputs, which is crucial for realistic exploration. The model also improved decision-making when integrated with models like large language models (LLMs).
Genex introduces an Imaginative Multi-Agent Reasoning capability, where agents simulate others' perspectives to enhance collaborative planning. This feature is pivotal for advancing embodied artificial intelligence in complex environments.
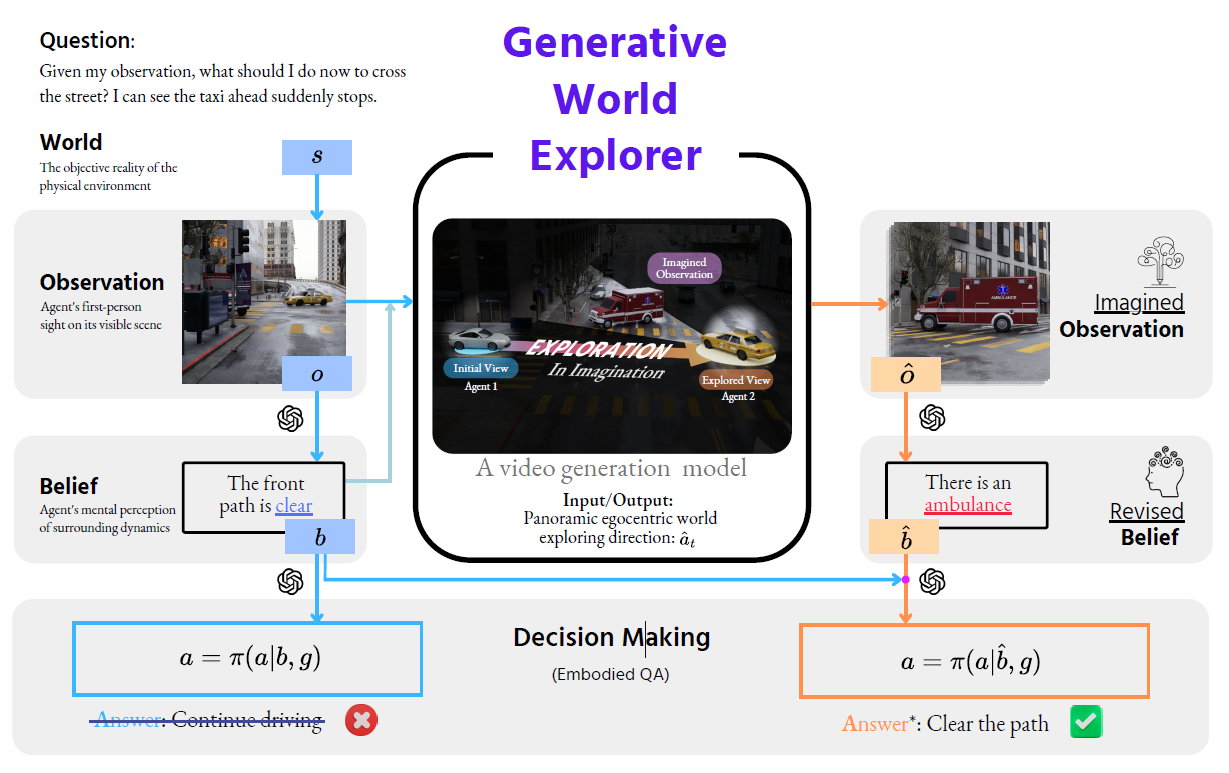
We propose the Generative World Explorer Genex that allows an agent to imaginatively explore a large-scale 3D virtual world and acquire imagined observation to update its belief. In this example, agent 1 (sliver car) imaginatively explores to the perspective at the location of agent 2 (taxi) with Genex. The imagined observation at agent 2’s position (including the explored ambulance) revises agent 1’s belief and enables more informed decision making.
Related Work
Past work on generative video modeling highlighted the effectiveness of diffusion models for video synthesis, with approaches like video diffusion models leveraging latent space denoising for controllable video generation.
Recent action-conditioned models synthesized visual plans but primarily addressed state transitions without modeling agent beliefs, a critical limitation for reasoning in partially observable environments. These limitations underscore the need for more comprehensive approaches to guide decision-making in complex, real-world tasks.
Genex: Imaginative World Exploration
Genex introduces two modes of exploration: goal-agnostic exploration, where agents freely navigate to understand their surroundings, and goal-driven exploration, guided by specific instructions such as reaching a target location.
Genex's macro-design includes video generation based on red, green, and blue (RGB) observations, with a multimodal large model configuring navigation directions and distances. The system updates panoramic forward views and generates navigation videos using a diffuser backbone, ensuring spatial consistency. Panorama images provide a 360-degree perspective, enabling seamless navigation and coherent updates through spherical transformations. This panoramic representation is particularly effective for maintaining environmental context across long distances.
The micro-design employs a stable video diffusion model and introduces spherical-consistent learning (SCL), a regularization technique that minimizes errors in latent spaces to preserve continuity across 360-degree views. Panorama images, represented in spherical coordinates, are converted into 2D or cubemap formats for compatibility with multimodal systems.
The SCL objective reduces errors in latent spaces, maintaining coherence across 360-degree views by applying rotational transformations during training. This ensures that generated videos remain consistent with the agent’s intended navigation path, even during extended exploration. Genex iteratively denoises latent inputs conditioned on initial RGB observations to generate realistic panoramic videos during inference.
Generative World Explorer
Imaginative Multi-Agent Reasoning
Embodied agents operate within a partially observable Markov decision process framework, where actions and observations shape belief updates and decision-making. Imagination-driven belief revision allows agents to simulate environments, effectively freezing time and exploring hypothetical scenarios without physical traversal.
By freezing time, agents construct imagined scenarios, explore hypothetical actions, and update beliefs based on simulated observations. This imaginative process approximates physical exploration, enabling agents to refine their beliefs and make informed decisions. Genex is employed for this imaginative exploration, while a large multimodal model handles policy and belief updates, improving decision-making accuracy.
In multi-agent scenarios, imagination-driven exploration enables agents to infer other agents' beliefs and perspectives, improving collaboration and adaptability. For instance, an agent predicts another's observations and integrates these insights to adjust its actions effectively. This approach supports complex tasks, such as multi-agent reasoning in dynamic environments.
To benchmark these capabilities, the team introduced Genex-embodied question answering (EQA), a dataset that evaluates agents' ability to navigate, mentally simulate, and solve multi-agent tasks under partial observation.
Genex Dataset Evaluation
The Genex dataset was constructed using Unity, Blender, and the Unreal engine. It generated four distinct scenes representing different visual styles, such as realistic, animated, low-texture, and geometry. A model was trained on each dataset, and cross-validation was conducted across all scenes to evaluate the generalization capabilities of navigational video diffusers.
Additional real-world test sets from Google Maps Street View and the Behavior Vision Suite highlighted the model's robust zero-shot generalizability. Genex outperformed baseline models, maintaining cycle consistency and background fidelity during extended exploration.
The dataset design also included single-agent and multi-agent conditions, enabling autonomous exploration and embodied tasks. Evaluation metrics, including FVD and SSIM, confirmed Genex's superior performance in generating realistic and spatially coherent videos compared to state-of-the-art methods.
Conclusion
To sum up, the Genex was introduced as a novel video generation model that enabled embodied agents to explore large-scale 3D environments and update their beliefs without physical movement. By utilizing innovative techniques like spherical-consistent learning (SCL), Genex generated high-quality, coherent videos during extended exploration.
The model integrated generative video into partially observable decision-making, enhancing agents' decision-making and planning capabilities. Genex also supported multi-agent interactions, advancing the development of more cooperative artificial intelligence (AI) systems and bringing embodied AI closer to human-like intelligence.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference: