Machine Learning in Astronomy
Machine learning has become increasingly popular in various fields, including astronomy, where combining diverse data types/modalities can provide a comprehensive understanding of celestial objects and phenomena. However, its use in astronomy is challenging due to limited labeled data, complex datasets, the need for specialized knowledge, and the inclusion of irregularly sampled time-series data, spectra, and various metadata essential for thorough analysis. To address these challenges, researchers have developed multimodal learning frameworks such as the "Contrastive Language-Image Pre-training (CLIP)" model, which has shown promising results in matching images with text.
AstroM3 extends the capabilities of CLIP by introducing a trimodal architecture explicitly tailored for astronomical datasets.
AstroM3: A Self-Supervised Multimodal Framework for Astronomy
In this paper, the authors proposed AstroM3, a model based on the CLIP framework that effectively learns joint representations from large-scale datasets. The AstroM3 architecture uses a shared embedding space to align data from all modalities, enabling seamless cross-modal comparisons.
AstroM3 extended CLIP to handle three data modalities: time-series photometry, spectra, and astrophysical metadata, thereby overcoming the limitations of existing models. This approach improves data efficiency and enables the model to generalize effectively across different datasets, which is important in astronomy, where labeled data is often limited.
The main goal was to develop a self-supervised multimodal model capable of learning from diverse astronomical data. The study utilized a large dataset of 21,440 objects, each containing time-series photometry, spectra, and metadata. This dataset was sourced from the variable star catalog of the "All-Sky Automated Survey for SuperNovae (ASAS-SN)," providing a robust foundation for training.
AstroM3 employs a trimodal architecture with specialized encoders for each data type. The photometric time-series data is processed using the "Informer model's encoder," which effectively captures temporal patterns. The spectral data is analyzed with an adapted "GalSpecNet architecture," specifically designed for the detailed examination of one-dimensional spectra. Metadata is processed by a "Multilayer Perceptron," which handles astrophysical parameters and observational data not included in the other two modalities. Each encoder is paired with a projection head to ensure all data modalities align in a shared representation space.
To align the representations from different modalities, the model employs projection heads that transform embeddings into a shared space, facilitating effective comparisons. Training is guided by a symmetric cross-entropy loss function, which aligns embeddings across modalities and enhances the model’s overall performance. This approach not only addresses the "small label" problem but also demonstrates the potential of leveraging large corpora of unlabeled data to enhance robustness.
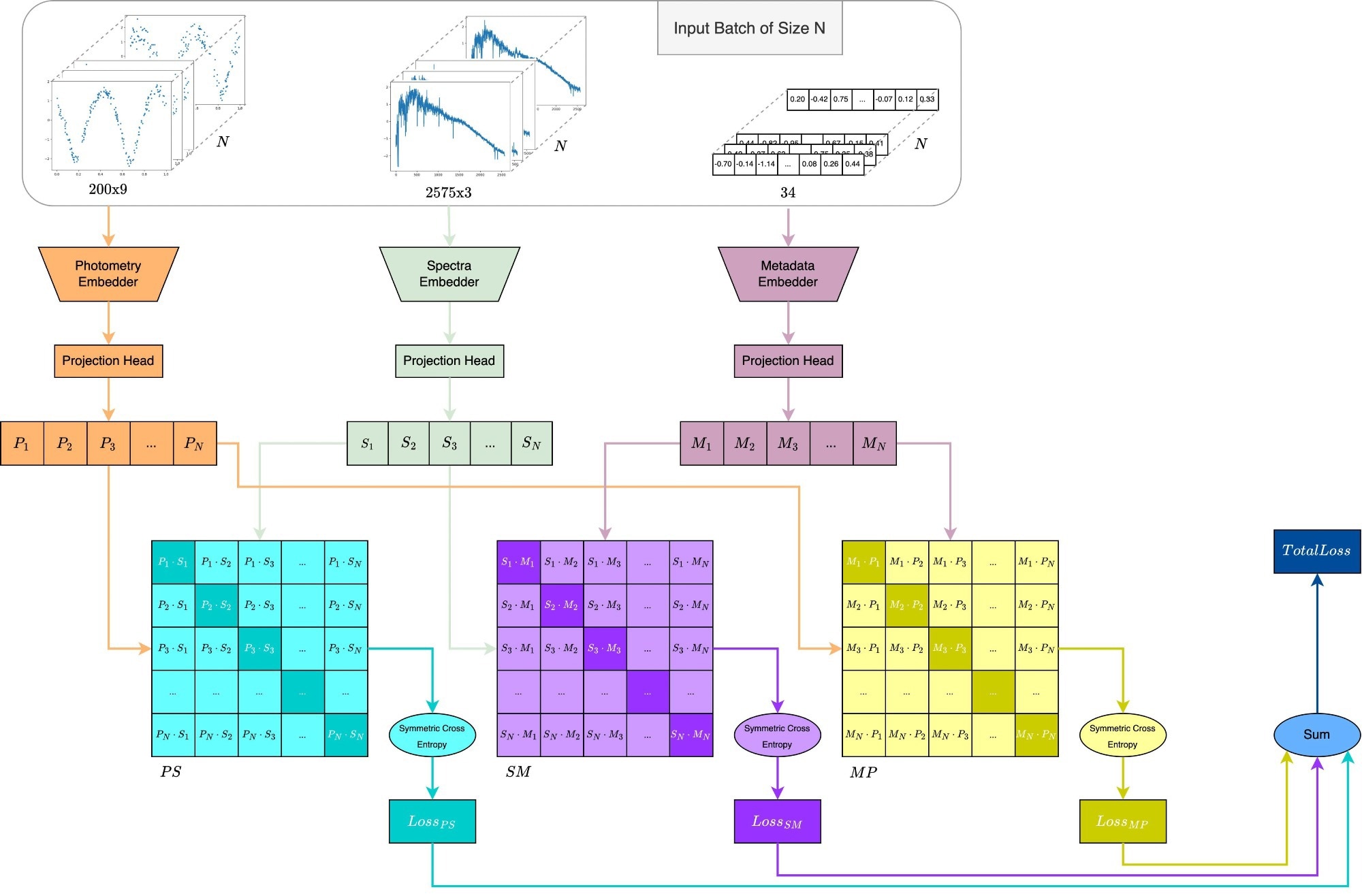
Overview of the multimodal CLIP framework adapted for astronomy, incorporating three data modalities: photometric time-series, spectra, and metadata. Each modality is processed by a dedicated encoder to create embeddings, which are then mapped into a shared embedding space through projection heads. Pairwise similarity matrices align the embeddings across modalities, and a symmetric cross-entropy loss, computed over these matrices, optimizes the model. The total loss, derived from all pairwise losses, guides the model’s trimodal learning.
Evaluation and Key Findings
The outcomes showed that CLIP pre-training significantly improved classification accuracy. For time-series photometry, accuracy increased from 84.6% to 91.5%. AstroM3 also demonstrated a 12.6% improvement in classification accuracy when labeled data was limited, highlighting its ability to leverage unlabeled data, a key challenge in astronomy. In particular, the model achieved remarkable stability in results, as evidenced by the reduced standard deviation in performance metrics.
The authors also revealed that the model could handle various downstream tasks beyond classification, such as identifying misclassifications and detecting anomalies. Remarkably, AstroM3 rediscovered distinct subclasses of variable stars, including Mira subtypes and rotational variable subclasses, using unsupervised learning. This rediscovery was achieved through clustering techniques, such as Uniform Manifold Approximation and Projection (UMAP), further underscoring the model's utility for exploratory data analysis. This ability to uncover hidden patterns in astronomical data highlights its potential to drive new scientific discoveries.
Applications of AstroM3
This research has significant potential for the field of astronomy, particularly in analyzing complex and diverse data, identifying misclassifications and outliers, and discovering new celestial objects and phenomena. AstroM3 supports targeted exploration of specific sources, helping astronomers better understand underlying physical processes. Its self-supervised learning nature makes it valuable for applications such as identifying rare astronomical events, classifying variable stars, and analyzing large-scale sky surveys.
The framework's capability to perform similarity searches within a shared embedding space enhances data exploration, enabling researchers to uncover previously missed phenomena. Additionally, its architecture allows for integrating new modalities, such as photometry from different wavelengths or human annotations. Future enhancements could include handling missing modalities during training, making the framework even more versatile for real-world datasets. This flexibility positions AstroM3 as a foundational tool for developing next-generation multimodal models in astronomy.
Conclusion and Future Directions
In summary, AstroM3 is an innovative, self-supervised multimodal framework that has the potential to revolutionize astronomy. Combining photometric, spectroscopic, and metadata modalities enables the analysis of complex and diverse data. Its strong performance, even with limited labeled data, makes it a powerful tool for utilizing large unlabeled datasets. By learning from diverse astronomical data, AstroM3 opens new avenues for scientific discovery, particularly in uncovering hidden patterns and subclasses.
Future work could expand the framework by incorporating additional data types and applying them to tasks like prediction and anomaly detection. Additionally, exploring its use in other fields, such as medicine and finance, where multimodal learning can offer valuable insights and enhance decision-making, would be an important direction. Another exciting possibility is applying AstroM3 to benchmark datasets from other surveys, further validating its potential as a foundational model for astronomy.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Rizhko, M., & Bloom, J. S. (2024). AstroM$^3$: A self-supervised multimodal model for astronomy. ArXiv. https://arxiv.org/abs/2411.08842