By addressing the limitations of existing methods, the researchers at Tencent AI Lab, Tsinghua University, and Beihang University developed an innovative approach that improves the quality, usability, and adaptability of 3D characters. Leveraging advanced technology, their method represents a significant contribution to the field of computer graphics and artificial intelligence (AI).
Advancement in 3D Character Creation
Generating realistic and versatile 3D characters has long been a major challenge in computer graphics and animation. Traditional methods are time-consuming and require extensive manual modeling and texturing.
The rise of deep learning models opened the door to automated 3D character generation from two-dimensional (2D) images, but early approaches had limitations. Challenges included achieving high-fidelity details, generating characters with distinct semantic parts (such as body, clothing, and hair), and the high computational cost of lengthy optimization processes.
Existing methods rely on parametric human models like SMPL-X, which are unsuitable for stylized characters with exaggerated features or use score distillation loss, leading to slow generation times and rough textures. While multi-view diffusion and large reconstruction models offer some improvements, they typically produce non-decomposable, watertight meshes that require extensive post-processing. Therefore, there is a pressing need for an efficient pipeline capable of creating high-quality 3D characters from single images.
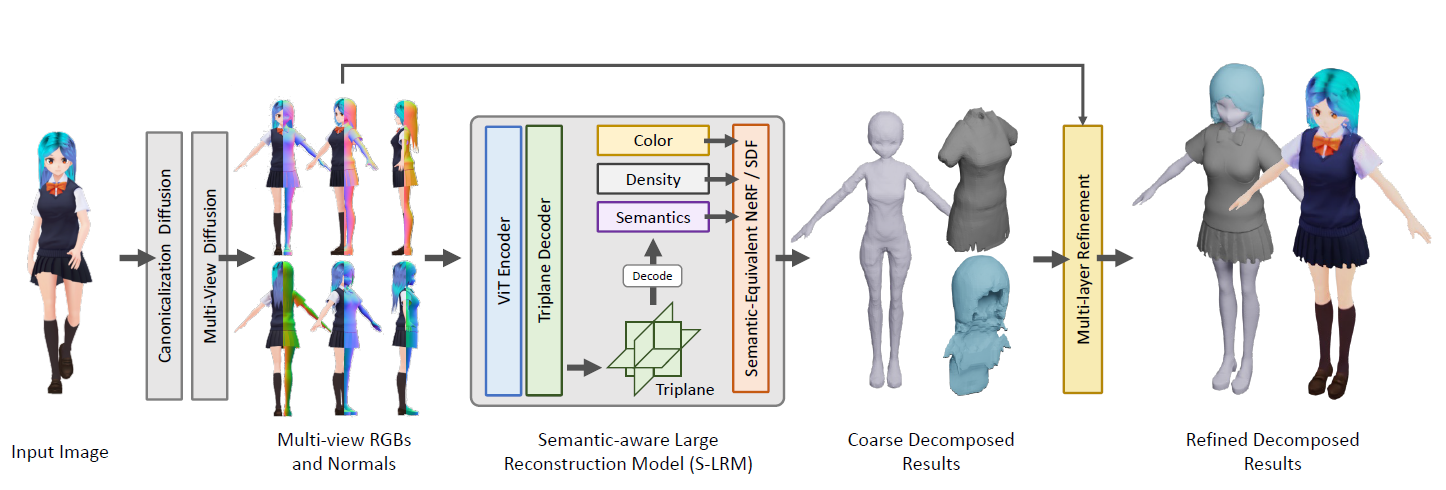 The overview of our StdGEN pipeline. Starting from a single reference image, our method utilizes diffusion models to generate multi-view RGB and normal maps, followed by S-LRM to obtain the color/density and semantic field for 3D reconstruction. Semantic decomposition and part-wise refinement are then applied to produce the final result.
The overview of our StdGEN pipeline. Starting from a single reference image, our method utilizes diffusion models to generate multi-view RGB and normal maps, followed by S-LRM to obtain the color/density and semantic field for 3D reconstruction. Semantic decomposition and part-wise refinement are then applied to produce the final result.
StdGEN: A Novel Approach for 3D Character Generation
In this paper, the authors developed StdGEN, a comprehensive pipeline designed to overcome the limitations of existing methods through a three-stage process: multi-view diffusion, feed-forward reconstruction, and mesh refinement.
The core innovation is the Semantic-aware Large Reconstruction Model (S-LRM), which uniquely combines geometry, color, and semantic information reconstruction using a feed-forward process. This transformer-based model reconstructs geometry, color, and semantic information from multi-view images in a feed-forward manner. This approach enables greater detail and segmentation than prior methods that treated the character as a single unit.
The multi-view diffusion stage generates multiple A-pose red-green-blue (RGB) images and normal maps from a single input image in any pose. S-LRM then processes these images to create a tri-plane representation, encoding the character’s geometry, color, and semantic segmentation.
Using a differentiable multi-layer semantic surface extraction scheme, separate meshes can be generated for individual components like body, clothing, and hair. The inclusion of a novel semantic-equivalent signed distance field (SDF) approach allows precise decomposition into layers while maintaining geometric consistency. Finally, a mesh refinement module enhances the quality of these meshes using diffusion-generated images and normal maps for guidance. This entire process takes only a few minutes, from a single input to a fully decomposed 3D character.
The study conducted extensive experiments using the Anime3D++ dataset, which the authors specifically developed to support the training and testing of the proposed method. This dataset includes finely annotated multi-view and multi-pose semantic parts of anime-style characters, allowing for robust evaluation of the StdGEN pipeline.
Performance Evaluation and Key Outcomes
The researchers comprehensively evaluated StdGEN’s performance against several state-of-the-art methods using quantitative metrics and a user study. Quantitative results demonstrated superior performance, as StdGEN achieved significantly higher scores in geometry, texture fidelity, and decomposability across metrics like SSIM, LPIPS, and FID. For instance, StdGEN achieved an SSIM of 0.958 for A-pose inputs, significantly outperforming CharacterGen’s 0.886.
A user study with 28 participants confirmed StdGEN’s superiority across quality dimensions, including overall quality, fidelity, geometry, and texture. The study showed that StdGEN was selected as the best approach 82.4% of the time for overall quality and 81.5% for geometric quality. Ablation studies underscored the importance of both semantic decomposition and multi-layer refinement. For instance, without semantic decomposition, mesh components fused into a single unit, limiting usability, and without multi-layer refinement, geometric precision, and texture fidelity were significantly reduced.
Notably, StdGEN created clothing with hollow internal structures, as seen in cross-sectional views, which supports applications like physics simulations and animation rigging. This capability ensures that clothing layers move independently from the character’s body, improving realism in motion. These experimental results confirmed that StdGEN surpassed existing methods in texture fidelity and geometric accuracy, paving the way for real-time 3D character generation applications where responsiveness and quality are essential.
Potential Applications
This research has significant implications for VR, augmented reality (AR), filmmaking, and gaming. In the gaming industry, generating high-quality, customizable 3D characters from single images can simplify character design, saving time and resources. The characters' decomposable nature also allows for dynamic changes, helping developers create more engaging and interactive experiences.
The rapid generation of realistic 3D characters in VR and AR boosts immersion and user engagement. Real-time character customization enables personalized experiences, enhancing the quality of virtual environments. In filmmaking, StdGEN offers advantages in creating complex character animations and visual effects. By enabling real-time customization and manipulation of characters, filmmakers can enhance storytelling and audience engagement.
Additionally, the decomposed meshes generated by StdGEN allow for easier rigging and animation. Unlike traditional models, which often have fused clothing and hair layers, StdGEN’s output supports detailed physical simulations, enabling a more lifelike representation in VR and AR environments.
Conclusion and Future Directions
In summary, the StdGEN pipeline proved effective for generating detailed 3D characters directly from single images in real time. Its efficiency, high-quality output, and decomposable design overcome many limitations of previous methods. With superior performance shown through metrics, user studies, and versatility across various applications, this pipeline is a valuable tool for industries that rely heavily on 3D character modeling.
By setting a new standard in efficiency and effectiveness, the presented technique demonstrates the feasibility of rapid character generation from single images. The research highlights the importance of semantic decomposition, which enhances model usability for downstream applications. Future work should focus on expanding StdGEN's capabilities to handle more complex scenes and characters with intricate details.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference:
- Preliminary scientific report.
He, Y., & et al. StdGEN: Semantic-Decomposed 3D Character Generation from Single Images. arXiv, 2024, 2411, 05738. DOI: 10.48550/arXiv.2411.05738, https://arxiv.org/abs/2411.05738