In an article submitted to the arXiv preprint server, an international team of researchers introduced a new model compression technique called preserving informative tokens using optimal merging with energy (PITOME). This novel approach enhanced transformer architecture efficiency by merging token representations more effectively while preserving the most essential information.
Unlike previous methods that used bipartite soft matching (BSM), which can lead to incorrect merges and loss of important data in later layers, PITOME employed an energy score based on graph energy theory to preserve informative tokens. This score helped identify large clusters for merging while protecting unique tokens. This method saved between 40-60% of floating-point operations per second (FLOPs) with minimal performance drops across tasks like image classification, image-text retrieval, and visual question answering (VQA). In theoretical analysis, PITOME maintained the spectral properties of the token space, preserving the intrinsic structure of token relationships.
Background
Past work on efficient attention mechanisms focused on speeding up transformer models using methods like hashing, low-rank, and sparse approximations or pruning strategies, though these often required extensive training. Token pruning approaches improved performance but complicated practical deployment with dynamic token counts.
Techniques like token merging (ToMe), using BSM, provided better speeds but struggled with heuristic merging, risking the loss of essential tokens. PITOME overcomes these challenges by combining the efficiency of BSM with a more robust and theoretically supported approach to token partitioning, maintaining accuracy while preserving spectral characteristics of the token space.
Optimized ToMe Method
The ToMe approach applies to each vision transformer (ViT) model’s transformer block. The standard block involves a self-attention mechanism and a multiple-layer perceptron (MLP). Through a carefully designed merging operation, ToMe compresses the output of the attention layer, reducing the token count while preserving crucial information. The compression relies on foundational matrices and selects a fraction of tokens for merging, facilitating efficiency improvements while minimizing computational costs.
 A comparison of token merging methods. Patches of the same color are merged. Green arrows highlight incorrect merges, avoided by PITOME. Position of tokens with high attention scores (cyan borders, zoom for clarity) in PITOME are maintained proportionality akin to ViT-base 384.
A comparison of token merging methods. Patches of the same color are merged. Green arrows highlight incorrect merges, avoided by PITOME. Position of tokens with high attention scores (cyan borders, zoom for clarity) in PITOME are maintained proportionality akin to ViT-base 384.
To manage ToMe, a novel energy-based method in PITOME evaluates token redundancy through a metric inspired by graph energy. The technique classifies tokens into protected and mergeable categories. A weighted graph represents token relationships, where edge weights are defined based on cosine distances between token embeddings. Based on their energy distribution, the energy score identifies tokens that can be merged (often background) and those that should be retained (important objects).
The merging process utilizes a BSM strategy that splits mergeable tokens into two sets, ensuring that tokens from similar objects merge with their nearest neighbors. This method balances merging efficiency and accuracy by accounting for energy scores. Changes to token sizes, managed with proportional attention, ensure that merged tokens contribute appropriately to the output.
Finally, the proposed PITOME method has theoretical underpinnings in the field of graph coarsening. It preserves the spectral properties of the original token graph, unlike the existing ToMe technique. This preservation is achieved by maintaining consistent spectral distances, ensuring that the merged token graph closely resembles the original. These differences are mathematically demonstrated, highlighting PITOME’s superiority in preserving essential graph characteristics.
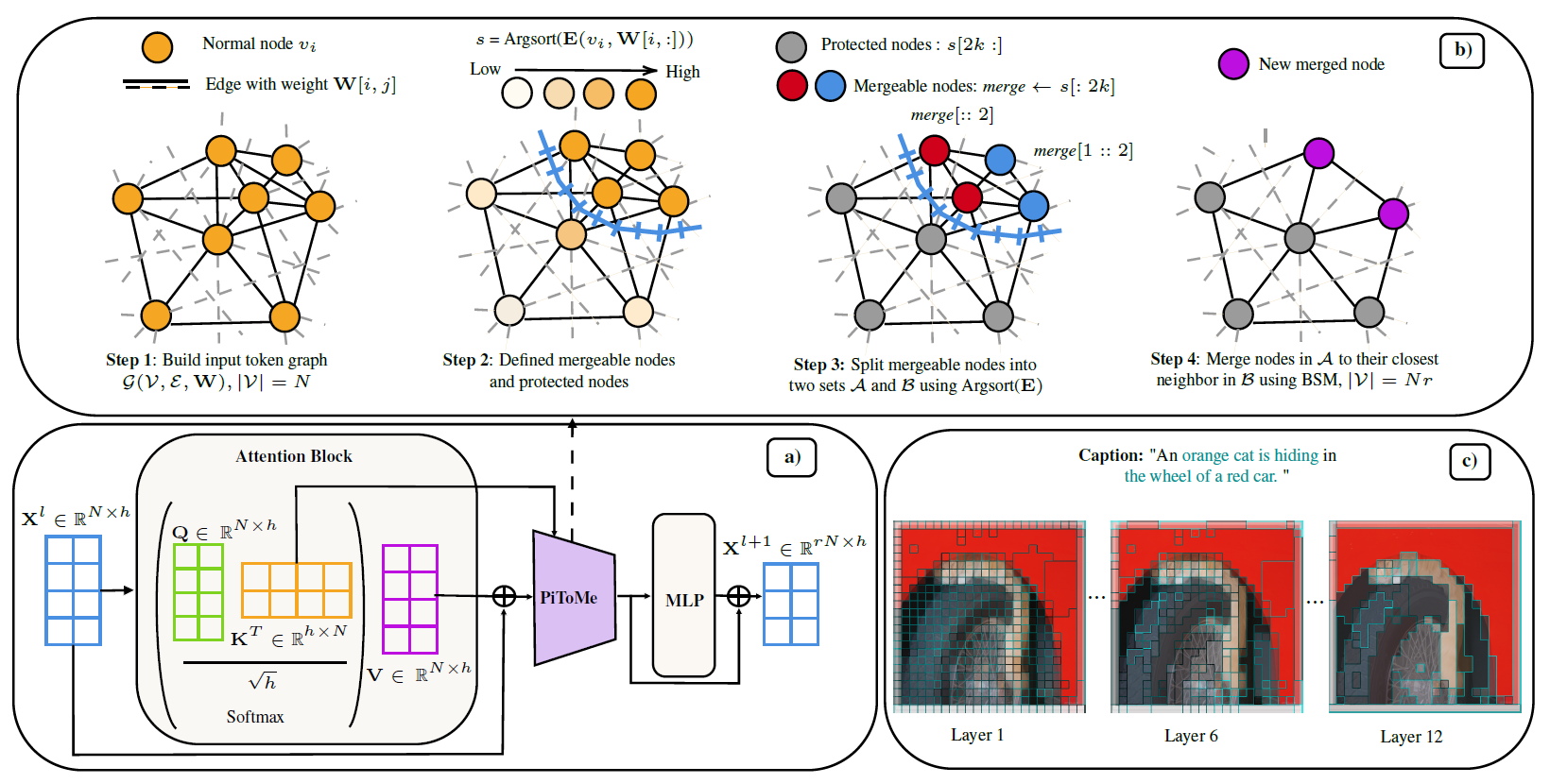 PITOME can be inserted inside transformer block; b) Energy scores are computed to identify mergeable and protective tokens; c) Our algorithm gradually merges tokens in each block.
PITOME can be inserted inside transformer block; b) Energy scores are computed to identify mergeable and protective tokens; c) Our algorithm gradually merges tokens in each block.
PITOME Compression Performance
The experiments evaluate PITOME in two settings: “off-the-shelf performance,” where models are tested immediately after compression without retraining, and “retrained,” where PITOME serves as a pooling function with models retrained on downstream tasks.
The focus is on four tasks: image-text retrieval, VQA, image classification, and text classification, tested on datasets such as Flickr30k and MSCOCO. The primary metric used for benchmarking is the number of FLOPS, which measures memory footprint and inference speed. Reduced FLOPS indicate increased memory efficiency and faster training and inference times.
PITOME was tested on vision-language models like CLIP, ALBEF, and BLIP. It outperformed state-of-the-art compression methods such as ToMe, ToFu, DiffRate, and DCT, significantly reducing memory footprints and improving speed by approximately 36%-56% in FLOPS, with 1.4x to 1.6x speedups over base models. Tests on larger models and batch sizes highlighted even more notable reductions in reranking times.
In the VQA task, PITOME was applied to large vision-language models like LLaVa and tested across six VQA datasets, including VQA-v2, GQA, and ScienceQA. PITOME showed significant gains in inference speed, nearly halving time compared to previous methods, and improving robustness in specific datasets, like VisWiz and ScienceQA. The results indicate that the compression strategy, which merges less significant tokens, not only reduces memory requirements but can even boost performance in certain contexts.
Conclusion
To sum up, this paper introduced PITOME, a novel algorithm that utilized graph energy-based concepts to protect informative tokens during the ToMe process. The algorithm demonstrated efficiency comparable to heuristic merging methods while maintaining a theoretical connection to the spectral properties of the input token space.
Experiments on image classification, image-text retrieval, and VQA with models such as LLaVa-1.57B/13B showed that PITOME outperformed recent ToMe and pruning methods in terms of runtime and memory usage. Future work may extend PITOME to generative tasks and optimize scalability by using sparse graphs and further exploring differentiable learning mechanisms.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Tran, H., et al. (2024). Accelerating Transformers with Spectrum-Preserving Token Merging. ArXiv. DOI: 10.48550/arXiv.2405.16148, https://arxiv.org/abs/2405.16148