Discover how SALAD, a cutting-edge AI model, uses continuous diffusion and self-supervised learning to generate highly intelligible, lifelike speech – even for voices it has never heard before.

Research: Continuous Speech Synthesis using per-token Latent Diffusion
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
In an article recently submitted to the arXiv preprint* server, researchers introduced a model called semantic adaptive latent diffusion (SALAD), a per-token latent diffusion model for zero-shot text-to-speech that utilizes continuous representations.
SALAD builds upon an expressive, per-token diffusion head initially developed for image generation and extends it for audio synthesis, allowing the model to produce variable-length outputs using semantic tokens for contextual information.
The study proposed three continuous variants and compared them against discrete baselines, revealing that continuous modeling is especially advantageous in maintaining intelligibility without sacrificing quality. Both approaches were effective, but SALAD achieved superior intelligibility metrics while matching ground-truth audio in speech quality and speaker similarity.
Background
Past work focused on zero-shot text-to-speech (TTS) systems that generalize to unseen speakers, enhancing flexibility and quality. SALAD utilized continuous, self-supervised semantic tokens derived from self-supervised audio models to capture phonetic information and assist in determining synthesis-stopping conditions.
While various methods predicted residual vector quantization (RVQ) codes, SALAD uniquely predicted a continuous latent space, eliminating the need for multiple residual codes and enhancing robustness to noise. Unlike existing diffusion models, SALAD employed variational autoencoder (VAE) latent tokens and a diffusion head to model multimodal distributions, enabling nuanced audio synthesis through semantic tokens that improve contextual comprehension.
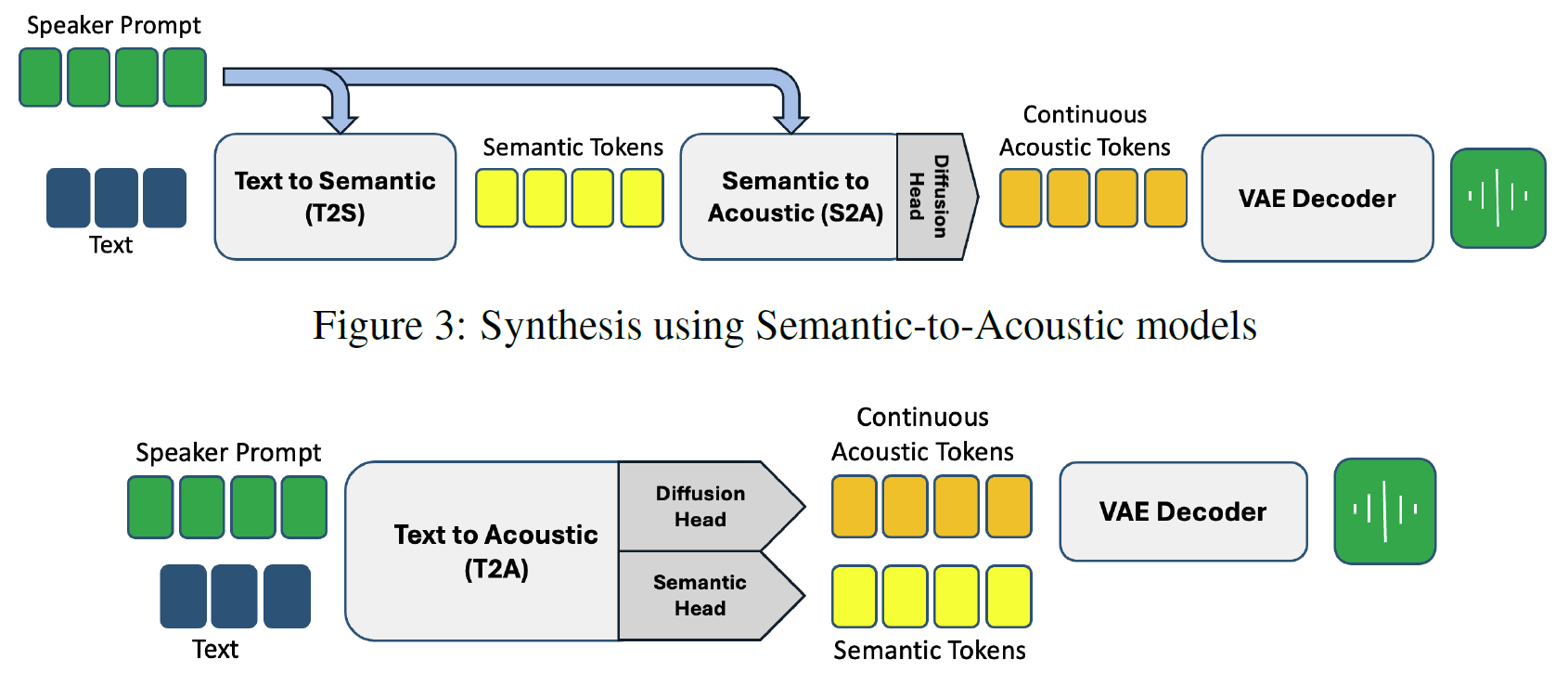 Synthesis using Text-to-Acoustic models.
Synthesis using Text-to-Acoustic models.
Audio Processing and Synthesis
The method presented involves processing raw audio sequences and converting them into compressed representations using a VAE. The VAE is designed to achieve high-fidelity audio reconstructions by employing adversarial losses during training. It generates sequences of means and variances from the raw audio, achieving efficient downsampling with a specific stride.
The continuous acoustic tokens are sampled from a normal distribution, and the VAE's decoder reconstructs the audio from these tokens. The model also extracts semantic tokens that are downsampled similarly to the VAE. These tokens allow the model to predict audio based on given text and speaker prompts with improved fidelity.
The diffusion process begins with a continuous signal, gradually introducing noise through a forward process. This approach enables nuanced prediction of the latent vectors generated by the VAE. The iterative denoising process simplifies the definition of the noise-corrupted signal.
Diffusion models are trained to reverse this process, denoising the corrupted signal by predicting the added noise. The loss function for training SALAD focuses on minimizing the difference between the expected and actual noise, moving the distribution toward a normal state over time.
Speech Quality Assessment Methods
The experimental setup involved training models on the English subset of the multi-lingual LibriSpeech (MLS) dataset, consisting of 10 million examples, leading to 45,000 hours of audio. To mitigate speaker overexposure, the maximum number of utterances per speaker was capped at 10,000, resulting in 5.2 million examples for training. The evaluation was conducted on the LibriSpeech test-clean set, which comprises 2,620 utterances from 40 distinct speakers, ensuring none of the speakers in the test set were included in the training dataset.
After filtering for utterance lengths between 8 to 25 seconds and limiting to a maximum of 15 samples per speaker, 564 utterances remained for evaluation. In the tokenization phase, SALAD utilized various models, including continuous β-VAE-generative adversarial networks (GANs) with different bottleneck dimensions and discrete RVQ-GAN models with multiple codebooks.
Semantic tokens were extracted by quantizing embeddings from a specific layer of Word2Vec bidirectional encoder representations from transformers (W2V-BERT) and further compressed using a byte pair encoding (BPE) tokenizer to refine token distribution. The main architecture was a transformer model with a dropout rate of 0.1 and a parameter count of 350 million.
Training utilized techniques such as classifier-free guidance and quantizer dropout, and all models underwent rigorous evaluation through metrics like audio quality (UTMOS), intelligibility (character error rate), and speaker similarity (cosine similarity).
Two subjective listening tests were conducted to assess perceptual quality, focusing on speech quality and naturalness using a mean opinion score (MOS) and speaker similarity through additional pairwise assessments.
Results highlighted that continuous models were competitive with their discrete counterparts, with the T2A model in SALAD achieving the highest intelligibility score. The subjective evaluations revealed minimal differences in perceptual quality between the ground-truth audio and both continuous and discrete models.
In an ablation study, the authors analyzed the impact of hyperparameters on synthesized speech quality, identifying trade-offs between intelligibility and similarity. Additionally, they examined the impact of VAE sampling on model robustness. Significant audio quality and intelligibility improvements were shown when sampling from the VAE distribution, suggesting this approach helps control artifacts during synthesis.
The SALAD approach facilitates zero-shot text-to-speech synthesis by predicting continuous VAE latents through a per-token diffusion head, with semantic tokens serving as contextual guides. It offers two variants: one that predicts acoustic features from semantic tokens and one that predicts both semantic and acoustic features directly from text.
The model incorporates discrete prediction architectures. It uses a quantizer to generate sequences of discrete codes for audio frames, employing both autoregressive and non-autoregressive methods with random unmasking during inference.
Conclusion
To sum up, compressing complex signals like audio and images involves a tradeoff between perception and generation, where compression could lead to information loss, potentially degrading performance. Although RVQ was a powerful compression method, it introduced quantization noise, while continuous representations demonstrated greater resilience against distortions.
Limitations identified included slower inference with the diffusion head compared to RVQ prediction heads and difficulty in optimizing the balance between discrete and continuous losses in the continuous T2A model. Future work aims to develop symmetric multimodal models and explore diverse inference strategies for performance gains.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Turetzky, A., et al. (2024). Continuous Speech Synthesis using per-token Latent Diffusion. ArXiv. DOI: 10.48550/arXiv.2410.16048, https://arxiv.org/abs/2410.16048