They introduced the Human Feedback (HF)-Embodied Dataset, a large-scale dataset containing over 35,000 samples, to train a human preference evaluator for visual fidelity assessment and evaluated video-action consistency in dynamic environments. This approach aimed to drive innovation in video generation models for embodied artificial intelligence (AI).
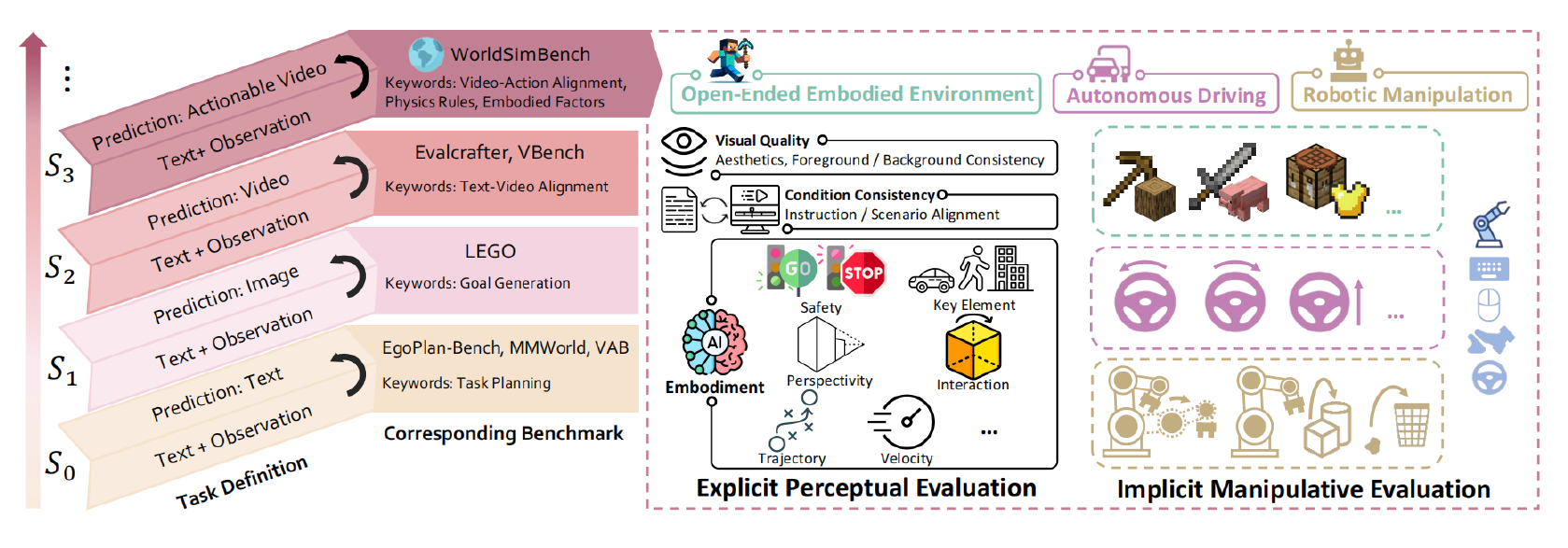
Overview of the hierarchical capabilities of the Predictive Models. Models at higher stages demonstrate more advanced capabilities. We take the initial step in evaluating Predictive Generative Models up to the S3 stage, known as World Simulators, by introducing a parallel evaluation framework, WorldSimBench. WorldSimBench assesses the models both Explicit Perceptual Evaluation and Implicit Manipulative Evaluation, focusing on video generation and action transformation across three critical embodied scenarios.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Background
Past work on predictive models demonstrated their ability to map current states to future ones across text, image, and video modalities. Predictive Text Models, built on large language models (LLMs) and multimodal LLMs (MLLMs), excelled in high-level planning for embodied agents. In contrast, predictive image models generate future goal images to aid decision-making.
Despite progress in predictive video models, limitations in training data and physical consistency hindered their broader applicability. Recent advances in diffusion transformers and large-scale video datasets have led to more accurate physical representations in world simulators, enabling more precise evaluations from an embodied perspective.
Comprehensive World Simulator Evaluation
WorldSimBench is designed to evaluate the embodied capabilities of World simulators across distinct hierarchical stages of complexity, labeled S0 to S3. The first, explicit perceptual evaluation, focuses on assessing simulators based on human-perceived quality across three specific scenarios: Open-Ended Environment, Autonomous Driving, and Robot Manipulation.
The second, implicit manipulative evaluation, indirectly assesses simulators by converting generated videos into control signals and observing their performance in real-time closed-loop embodied tasks. These scenarios create diverse evaluation benchmarks with varied complexity, from the open-ended nature of Minecraft as a testbed to the structured environments of autonomous driving and robotic manipulation.
A hierarchical evaluation checklist is created for explicit perceptual evaluation to assess three main aspects: visual quality, condition consistency, and embodiment. Visual quality evaluates aesthetics and consistency, condition consistency focuses on how well the videos align with instructions, and embodiment examines physical interactions like accurate movement trajectories.
The HF-Embodied Dataset, which contains human feedback in 20 dimensions, is used to train a human preference evaluator, a video scoring model that assesses videos based on multiple dimensions aligned with human perception standards.
In implicit manipulative evaluation, the World simulator is treated as a low-level decision-maker for various tasks. By using pre-trained video-to-action models, the predicted future videos generated by the World simulator are transformed into executable control signals. This approach allows continuous and adaptive assessment of the simulator’s performance in real-time simulation environments.
Finally, evaluation metrics are defined for each scenario to measure performance. In Open-Ended Environments (OE), metrics like travel distance and item collection are tracked, while in Autonomous Driving (AD), metrics such as route completion and driving score are used. For Robot Manipulation (RM), success rates in specific tasks like robot manipulation are calculated. These metrics provide a detailed evaluation of the effectiveness and adaptability of World simulators across various real-world tasks.
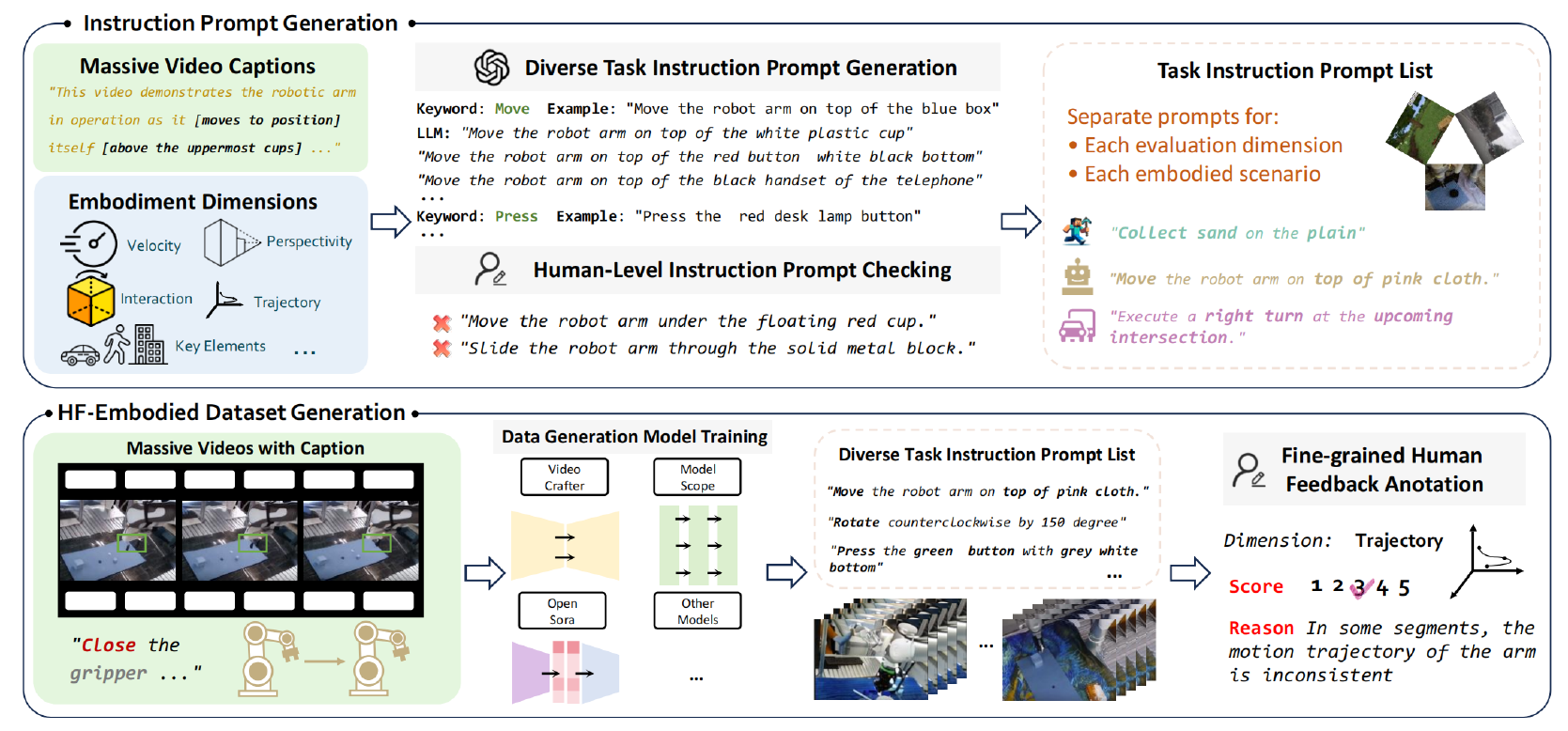 Overview of Explicit Perceptual Evaluation. (Top) Instruction Prompt Generation. We use a large collection of video captions from the internet and our predefined embodied evaluation dimensions. These are expanded using GPT and manually verified to create a corresponding Task Instruction Prompt List for data generation and evaluation. (Bottom) HF-Embodied Dataset Generation. Massive internet-sourced embodied videos with captions are used to train data generation models. Fine-grained Human Feedback Annotation is then applied to the embodied videos according to the corresponding Task Instruction Prompt List, covering multiple embodied dimensions.
Overview of Explicit Perceptual Evaluation. (Top) Instruction Prompt Generation. We use a large collection of video captions from the internet and our predefined embodied evaluation dimensions. These are expanded using GPT and manually verified to create a corresponding Task Instruction Prompt List for data generation and evaluation. (Bottom) HF-Embodied Dataset Generation. Massive internet-sourced embodied videos with captions are used to train data generation models. Fine-grained Human Feedback Annotation is then applied to the embodied videos according to the corresponding Task Instruction Prompt List, covering multiple embodied dimensions.
Video Generation Evaluation
WorldSimBench evaluated eight popular video generation models, including Open-Sora-Plan, Lavie, and ModelScope, through explicit perceptual and manipulative evaluations across the three embodied scenarios of OE, AD, and RM. The models were fine-tuned on datasets corresponding to each scenario, ensuring they aligned with specific evaluation criteria.
Five instruction prompts were used to guide video generation for explicit perceptual evaluation, and the human preference evaluator scored the videos based on comprehensive human-perceived quality measures. In OE, video quality was assessed on a binary scale, while AD and RM used a 1-5 scale for a broader evaluation range.
In Implicit Manipulative Evaluation, pre-trained video-to-action models transformed the predicted videos into control signals for real-time tasks in simulated environments. Datasets like video pretraining (VPT), Calvin, and Carla were used to train these models.
Each evaluation tracked specific metrics, such as travel distance and item collection in OE, route completion in AD, and success rates in RM. The results revealed that models struggled with generating physically plausible interactions, especially in OE, where complex physical rules like object deformations were not accurately captured. The human preference evaluator outperformed generative pre-trained transformer version 4 (GPT-4o) in aligning with human preferences across all scenarios, demonstrating broad generalization even in zero-shot experiments. However, models still faced challenges in maintaining 3D depth and embodied realism, underscoring the need for improvements in generating consistent, physically plausible content.
The evaluation of video generation models in WorldSimBench revealed that, although some models excelled in specific tasks, significant improvements are necessary for reliable embodied intelligence in real-world simulations. Current models must better align with physical laws and produce high-quality videos across a range of tasks.
Conclusion
In summary, this method classified the functionalities of predictive models according to embodied stages and proposed a dual evaluation framework called WorldSimBench for assessing World simulators. Video generation models were comprehensively evaluated using both explicit perceptual and manipulative evaluation processes.
Key findings were summarized to inspire future research on World Simulators, although limitations were acknowledged as the current evaluation focuses on embodied intelligence. This highlights the need for further exploration in assessing World simulators across more diverse scenarios and physical representations.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Qin, Y. et al. (2024). WorldSimBench: Towards Video Generation Models as World Simulators. ArXiv. DOI: 10.48550/arXiv.2410.18072, https://arxiv.org/abs/2410.18072