The rapid rise of digital communication, especially on social media, has brought humor and satire to the forefront. Satirical images often present conflicting scenarios that rely on visual elements and contextual clues.
Understanding satire involves more than just recognizing objects in an image; it requires interpreting the irony, humor, or exaggeration that creates a satirical twist. This makes it especially challenging for VL models, which depend on large datasets, to learn the relationships between visual and textual elements.
Despite advancements in VL models, decoding satire remains one of the most challenging forms of humor. Unlike straightforward image classification, satire demands higher-order reasoning and cultural awareness. As satire plays a key role in social commentary, especially in memes and other internet formats, developing models that detect and understand satire presents a significant technological challenge. The study used pre-trained VL models in a zero-shot setting, meaning the models had not been fine-tuned specifically for satire comprehension, thereby testing their generalization capabilities in this nuanced domain.
YesBut: A Novel Dataset
In this paper, the authors proposed YesBut by carefully curating 2,547 images, including 1,084 satirical and 1,463 non-satirical samples. Each satirical image consists of two sub-images: one depicting a normal scenario and the other presenting an ironic or contradictory twist.
The dataset covers various artistic styles and features scenarios where humor is conveyed visually without relying on text. These elements create a rich testing ground for evaluating how well models can detect the subtle cues indicating satire.
One notable aspect of YesBut is its inclusion of both synthetic and real satirical images. The researchers manually annotated 283 real images from the @yesbut handle on X (formerly Twitter), while synthetic images were generated using DALL-E 3, creating combinations of 2D and 3D stick figures with satirical punchlines. Real photographs were sourced to test the models' abilities further. The dataset's diversity challenges models to understand satire in different visual contexts, including images without textual cues, requiring the models to rely solely on visual clues.
The researchers collected satirical images from social media, particularly from the X (formerly Twitter) handle @_yesbut_. Qualified annotators manually annotated these images, providing textual descriptions for each sub-image and the overall satirical context. Additionally, the annotators assigned a difficulty level (Easy, Medium, or Hard) to each satirical image based on how challenging it was to interpret, adding an extra layer of complexity for evaluating model performance. To enhance the dataset’s diversity, the study used the DALL-E 3 model to generate additional synthetic images in two-dimensional (2D) and three-dimensional (3D) stick figure styles, further expanding the dataset with new combinations of sub-images.
Effectiveness of VL Models
The study evaluated whether state-of-the-art VL models, including well-known models like the generative pre-trained transformer version 4 (GPT-4), Gemini, large language and vision assistant (LLaVA), MiniGPT-4, and Kosmos-2, could effectively perform three distinct tasks.
The first task was satirical image detection, where the models needed to classify images as satirical or non-satirical. The second task involved satirical image understanding, requiring the models to generate a textual description explaining the humor or irony of a given satirical image. The third task focused on satirical image completion, where models had to complete a partially visible satirical image by selecting from two options, with one option providing the correct satirical punchline.
Notably, the models were evaluated in both zero-shot and zero-shot CoT settings, the latter designed to encourage step-by-step reasoning. However, despite the use of CoT prompting, performance improvements were minimal, indicating the task's inherent difficulty.
Key Findings: Gaps in Satire Comprehension
The outcomes showed that existing VL models face significant challenges in understanding satire. The YesBut dataset provided a tough benchmark, with even the top-performing models achieving only moderate success.
For example, none of the models scored higher than 60% in accuracy or F1 scores in detecting satirical images. Kosmos-2 performed best in the detection task, achieving a 59.71% F1 score in zero-shot settings. However, even with CoT prompting, only minor improvements were observed in most models. This suggests that the models struggled to distinguish between satirical and non-satirical photos, indicating that satire detection remains unresolved.
In understanding satirical images, the models were asked to explain why an image was satirical. The evaluation revealed that the models had difficulty generating coherent and accurate explanations, with average scores below 0.4. Despite Kosmos-2's multimodal grounding capabilities, the models' performance on lexical overlap metrics like BLEU and ROUGE remained weak, further underlining the complexity of satire comprehension.
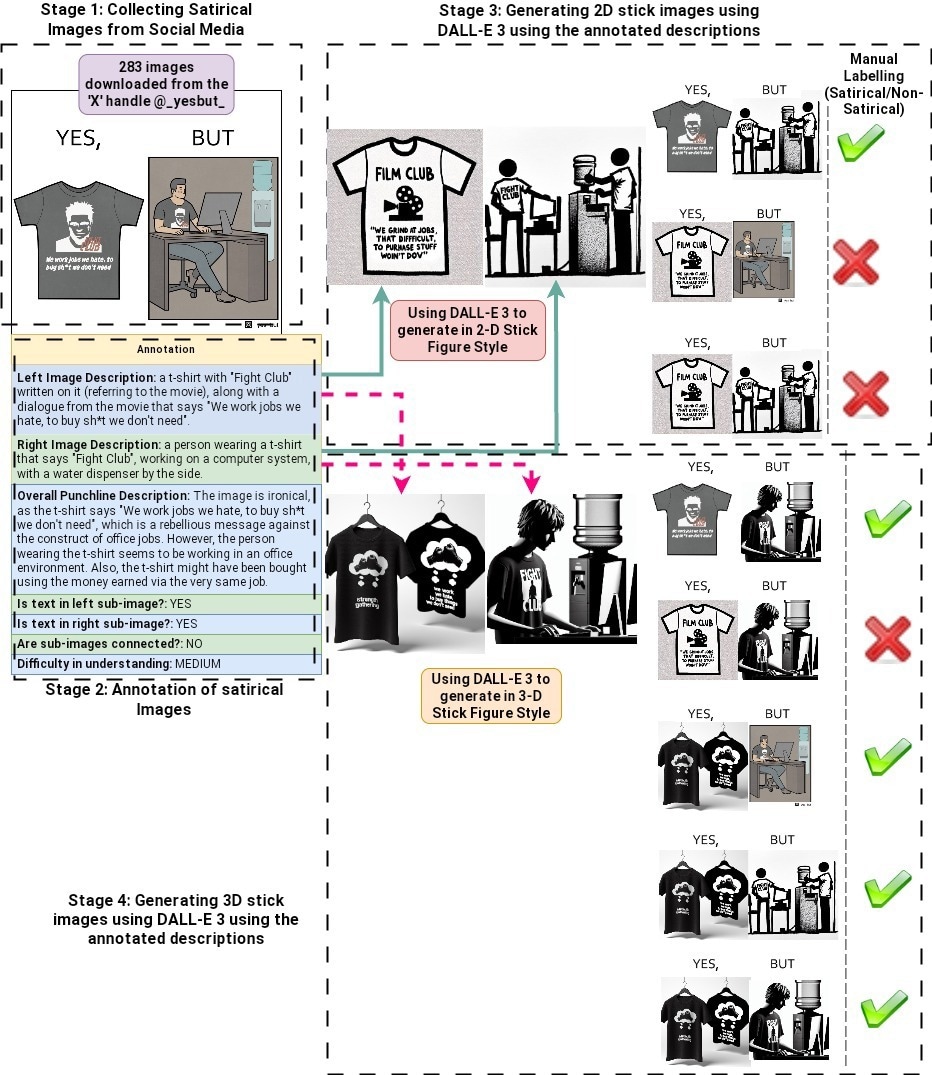
Our annotation Pipeline for YesBut in 4 Stages - (1) Collecting Satirical Images from Social Media (2) Human Annotation of satirical images (3) Generating 2D stick images using DALL-E 3 and annotated descriptions (4) Generating 3D stick images using DALL-E 3 and annotated descriptions
While Kosmos-2 performed better than other open-source models due to its multimodal grounding capabilities, the models did not achieve human-level understanding overall. They struggled to grasp the humor or irony that made the images funny and had trouble understanding the relationship between the two sub-images in a satirical context.
In the image completion task, where models needed to choose the correct second half of a satirical image, performance was again weak. Gemini outperformed others in this task, scoring 61.81% with CoT prompting. Although some improvements were made using chain-of-thought prompting, a method that helps models break down reasoning step-by-step, the models still failed to consistently complete the images in a way that maintained the satire.
Applications
This research has significant implications for developing more advanced VL models. By providing a benchmark for satire comprehension, it promotes the creation of models that can understand complex content. This has potential in social media analysis, automated content moderation, and developing more engaging and context-aware AI systems.
Understanding satire and humor is essential for AI systems to interact naturally with humans. Improved satire comprehension can enhance AI's ability to detect harmful or misleading content, leading to safer and more effective communication platforms.
Additionally, the proposed dataset can help train models to identify harmful or inappropriate content often concealed within satirical humor. Recognizing when satire becomes offensive or dangerous is a valuable tool for moderation on platforms relying heavily on user-generated content.
Conclusion
In summary, the novel dataset proved to be a valuable resource for evaluating the satirical comprehension abilities of VL models. However, the researchers highlighted the limitations of existing VL models in understanding satire.
While models like GPT-4 and Gemini have progressed in other visual and language understanding areas, satire remains a significant challenge. This is particularly evident in the models' low F1 scores across detection, understanding, and completion tasks despite using zero-shot and CoT prompting approaches.
Future work should focus on enhancing these models' cultural and contextual reasoning capabilities by training them on more nuanced datasets, integrating real-world knowledge, and expanding the range of satire and humor they can understand.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Journal reference:
- Preliminary scientific report.
Nandy, A., & et, al. YesBut: A High-Quality Annotated Multimodal Dataset for evaluating Satire Comprehension capability of Vision-Language Models. arXiv, 2024, 2409, 13592. DOI: 10.48550/arXiv.2409.13592, https://arxiv.org/abs/2409.13592