The approach reduced memory demands, making it efficient for handling extended contexts without requiring expensive training. Experiments showed improved performance and memory efficiency, broadening LLM usability in long-context tasks.
Background
LLMs have achieved significant success in natural language processing tasks, powering various applications. However, their primary limitation lies in the context window, restricting the amount of input they can process. This poses challenges in tasks requiring long-form understanding, such as extended chat history or large codebases.
Previous attempts to address this issue primarily focused on reducing the quadratic computational cost of the self-attention mechanism, employing techniques like sparse attention and linearized attention. While these methods have shown promise, they often necessitate significant architectural changes and are not easily scalable to larger models.
Recent research has concentrated on extending the context length by modifying positional encoding techniques, yet these approaches fail to address the computational inefficiency. To bridge this gap, the current paper introduced HOMER, a hierarchical context merging technique that divided inputs into chunks and merged them progressively to extend the context limit.
Unlike prior methods, HOMER achieved efficiency without fine-tuning pre-trained models, making it applicable in resource-constrained environments. Through extensive experiments, the paper demonstrated HOMER's superior performance in tasks like passkey retrieval and question answering, establishing it as an effective solution for handling long input sequences efficiently.
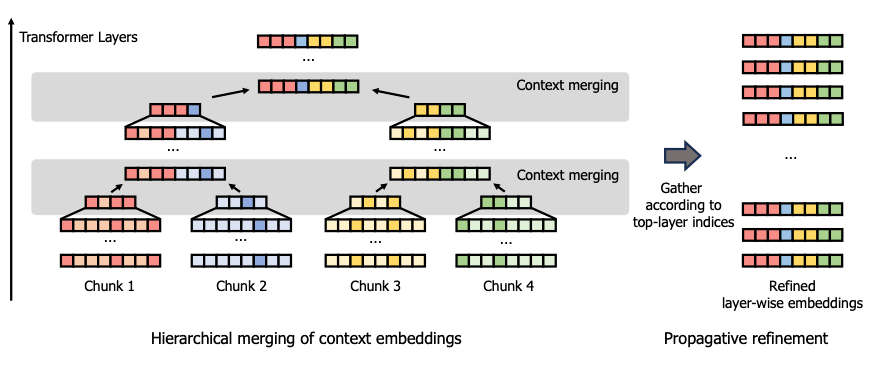
Hierarchical merging of context embeddings
Efficient Context Merging in LLMs
The proposed HOMER method addressed the challenge of efficiently extending the context limit of LLMs. HOMER operated in two key phases: hierarchical merging and propagative refinement. In the first phase, long contexts were divided into smaller chunks and processed through transformer layers. The token reduction was applied before merging adjacent chunks to avoid the high computational cost. This progressive merging reduced the overall number of tokens while maintaining rich context information across layers.
The second phase, propagative refinement, involved pruning tokens across both upper and lower layers. By doing so, the model standardized the embeddings at each layer to a fixed length, which could then be used as a key value (kv)-cache for efficient further processing. This process significantly reduced memory requirements, allowing for extended context processing without the need for retraining.
HOMER's design included an optimized computation order that enabled memory efficiency, scaling logarithmically with input length. Implementing a depth-first search (DFS) approach during hierarchical merging allows the method to handle large inputs in memory-limited environments, making it a versatile solution for long-context tasks in LLMs. This allowed LLMs to process extensive input sequences even in resource-constrained settings.
Evaluation and Performance Analysis
The evaluation began with passkey retrieval tasks, showing that HOMER could efficiently handle long contexts, maintaining high accuracy (around 80%) even with inputs of up to 32 thousand (k) tokens, far exceeding the original context length.
The authors assessed HOMER's performance in question answering, revealing an accuracy improvement of over 3% compared to the plain Llama model. Additionally, when combined with the neural tangent kernel (NTK) baseline, HOMER achieved a notable accuracy of 38.8%.
Fluency was tested using perplexity measurements on long documents from the Project Gutenberg (PG)-19 dataset. HOMER consistently maintained low perplexity across extended contexts, up to 64k tokens, unlike other methods that degraded with longer inputs. The researchers explored the effectiveness of HOMER's design choices, including token pruning and embedding refinement, demonstrating superior performance through careful attention-based token pruning and propagative refinement.
The authors highlighted HOMER's computational efficiency, showing significant reductions in peak graphics processing unit (GPU) memory usage—over 70% less for 64k inputs—compared to other methods. This efficiency was attributed to HOMER's chunking mechanism, token reduction, and optimized computation processes, which collectively enhanced both memory usage and processing speed.
Conclusion
In conclusion, the researchers introduced HOMER, a novel approach designed to overcome the context-limit constraints of LLMs. HOMER efficiently handled long contexts by hierarchically merging smaller input chunks, significantly reducing memory requirements without necessitating model retraining. The experiments demonstrated HOMER's effectiveness in maintaining high accuracy and low perplexity even with extended inputs of up to 64k tokens.
By optimizing memory usage and computational efficiency, HOMER enhanced LLM performance for tasks requiring extensive context. Future work may explore combining HOMER with fine-tuning techniques to improve performance, potentially offering extended context limits and enhanced model capabilities.
 *Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
*Important notice: arXiv publishes preliminary scientific reports that are not peer-reviewed and, therefore, should not be regarded as definitive, used to guide development decisions, or treated as established information in the field of artificial intelligence research.
Source:
Journal reference:
- Preliminary scientific report.
Song, W., Oh, S., Mo, S., Kim, J., Yun, S., Ha, J.-W., & Shin, J. (2024). Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs. ArXiv.org. https://arxiv.org/abs/2404.10308v1