A study recently published in the Journal of Imaging introduced a transformer-based system, BlinkLinMulT, designed to detect eye blinks. Unlike most current methods that focus on classifying eye states frame by frame, this approach effectively merges sequences of features at different levels, using cross-modal attention mechanisms with linear complexity.
 Study: BlinkLinMulT: A Transformer-Based System for Efficient Eye Blink Detection. Image credit: Gorodenkoff/Shutterstock
Study: BlinkLinMulT: A Transformer-Based System for Efficient Eye Blink Detection. Image credit: Gorodenkoff/Shutterstock
Background
Many facial analysis problems, including deep fake manipulation, spotting drowsy drivers, measuring attentiveness and eye strain during the execution of tasks, and detecting health issues, may be solved by detecting eye blinks. Even with the growing popularity of transformer-based sequence models in numerous additional study fields, most methods rely on the identification of faces and frame-wise eye state categorization. However, these techniques could have trouble dealing with situations where blinks last only a couple of frames or when the input data are erratic or lacking.
The machine learning and computer vision sectors employ various visual representations to solve the blink detection challenge. In the past ten years, three categories have emerged:
- Iris and ocular landmark distances are examples of higher-level characteristics that feature-based approaches employ.
- Appearance-based techniques categorize different eye states by employing learning algorithms using low-level eye depictions (such as red-green-blue (RGB) texture).
- Motion-based approaches employ a succession of eye-related characteristics or input representations that contain motion data in order to detect eye states.
The Proposed System - BlinkLinMulT
In computer vision and human-computer interaction, leveraging head pose information plays a pivotal role, especially during interpersonal exchanges. In such scenarios, individuals often shift their gaze downwards, revealing their upper eyelids. This subtle cue, though, poses a challenge for Convolutional Neural Networks (CNNs), as they primarily operate on individual frames. Thus, the integration of sequence models becomes imperative, given their ability to harness temporal information. Detecting these shifts can be facilitated by providing the network with head pose angles, typically predicted using methods like 3DDFA_V2.
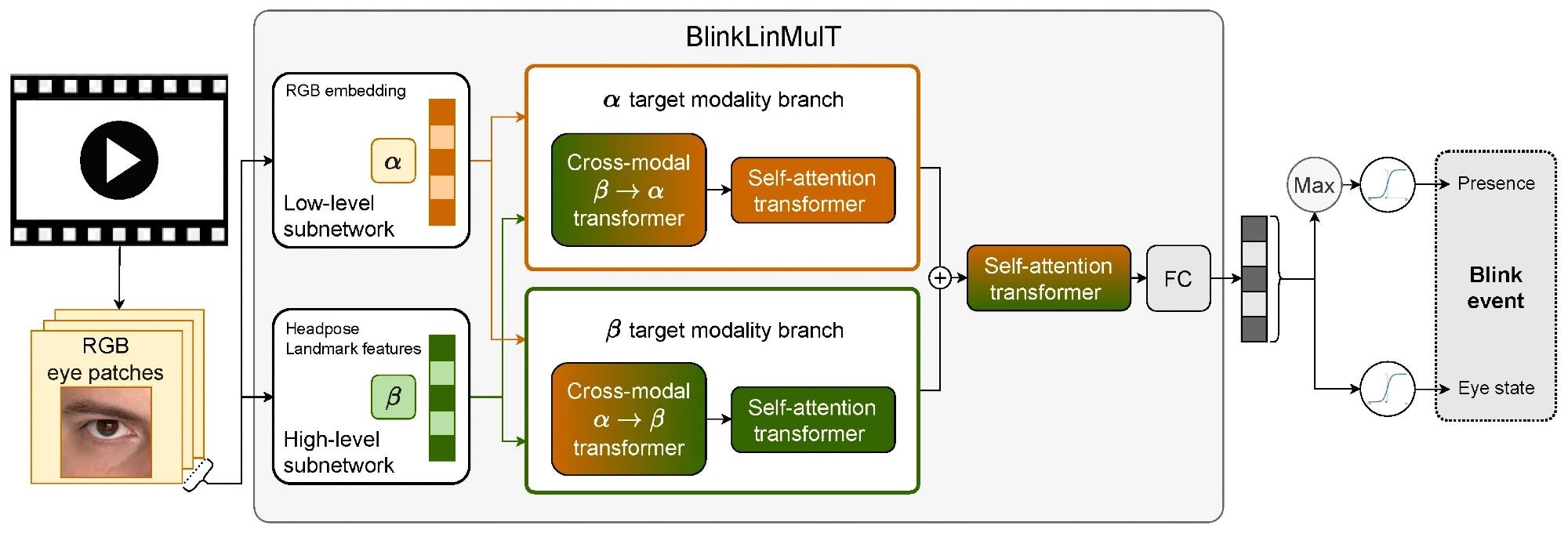 BlinkLinMulT: a multimodal transformer architecture for blink presence detection and frame-wise eye state recognition.
BlinkLinMulT: a multimodal transformer architecture for blink presence detection and frame-wise eye state recognition.
The proposed solution, named BlinkLinMulT, is a rapid multimodal transformer tailored for the detection of blink presence and eye state recognition. BlinkLinMulT takes diverse inputs, including embeddings from RGB texture data and outputs from pre-trained deep models. To further enhance information integration, a self-attention transformer operates branch-wise within the sequence. The output sequences from the modality branches are connected and fused using a self-attention transformer. Moreover, linear attention mechanisms are employed to enhance efficiency by optimizing computational resources.
A final layer of fully connected neurons serves two key purposes: determining the presence of blinking in the sequence and estimating eye states on a frame-by-frame basis. The network's outputs consist of logits, which are subjected to sigmoid activation during training and inference.
The blink estimation pipeline entails several steps. Initially, frames from the video are extracted, and when necessary, face detection and tracking are performed. A window of 0.5 seconds, covering the typical blink duration, is analyzed.
Datasets
A total of five video datasets and four image datasets were utilized in this experiment, some of which are discussed in this section briefly.
- The Closed Eyes in the Wild (CEW) dataset, introduced by Song et al., consists of close-face crops from various subjects.
- The ZJU eye blink dataset, initially introduced by Song et al. and expanded for this research, serves as another valuable resource.
- The MRL Eye dataset offers a diverse collection of 84,898 infrared images captured under different sensors and lighting conditions.
- Incorporating video data, the RT-GENE dataset was shot using a Kinect v2 RGB-D camera, capturing high-resolution RGB images.
- The EyeBlink8 dataset comprises eight videos shot in a home environment. These videos capture four participants and provide annotations for 408 eye blinks across 70,992 frames, showcasing real-world blink occurrences.
- TalkingFace, a 200-second video stream, focuses on evaluating facial landmark detection precision. It features a single participant speaking in front of the camera, with annotations available for 61 eye blinks.
- The Researcher's Night dataset, collected during Researcher's Night 2014, encompasses 107 videos with 223,000 frames.
Discussion and conclusion
This paper introduces an innovative approach to efficient eye blink detection, named BlinkLinMulT, which leverages a transformer-based model. The core of this model is the multimodal transformer with linear attention (LinMulT), which effectively combines diverse inputs, including RGB texture, iris and eye landmarks features, and head pose angles. The study sheds light on the impact of eye patch dimensionality on the performance of state-of-the-art backbones, such as CLIP ViT-B/16, emphasizing the critical role of considering motion dynamics versus frame-wise evaluations.
An essential aspect of their work is a feature significance ablation study, which underscores the effectiveness of their proposed method even in the case of extreme head poses. The experimental results reveal that BlinkLinMulT achieves performance on par with or superior to existing models in tasks related to blink presence detection and eye state recognition when tested on publicly available benchmark databases.
What makes BlinkLinMulT stand out is its adept utilization of transformers, facilitating the seamless fusion of input features. This proficiency is particularly evident in challenging real-world scenarios, demonstrating the model's robustness. In essence, BlinkLinMulT shows how the synergy of transformer technology can contribute to more accurate and versatile blink detection, addressing the demands of real-world scenarios.
 AI Reads Rock Thin Sections To Predict Reservoir Quality
AI Reads Rock Thin Sections To Predict Reservoir Quality